
Use-Case
Developers use BigQuery on Google Cloud Platform (GCP) for ad hoc analysis. It is also used to build operational dashboards and process data using stored procedures. The analysis cost of using this service is determined by the size of the data processed by queries issued on GCP BigQuery pricing. Under the current on-demand pricing model, this price can range from $5/TB in the US (multi-region) to $6/TB in Belgium (Europe-west1).
This essentially means that if developers fire lots of unoptimized queries, they can rack up thousands of dollars in cost. This case is also quite common in large organizations, especially those on pay-as-you-go models.
In terms of cost monitoring at the user level, currently, GCP does not disclose BigQuery pricing granular usage. The billing dashboard shows that the cost comes from BigQuery. However, it cannot be drilled down to identify specific users and activities causing these cost spikes. As such, the issue cannot be remediated.
An Innovative Solution
One workaround for this is to use the built-in and natively available BigQuery INFORMATION_SCHEMA metadata tables. Users can also build more specifically, the BigQuery jobs metadata table. The INFORMATION_SCHEMA.JOBS_BY_PROJECT table can be queried to see project-level query history for the past 180 days.
The metadata, which will be described in more detail in the next section, includes the user email and job ID. It also includes the amount of data queried and the query execution time, among other things. While query cost is not explicitly a column, it can be calculated using the column. It shows bytes billed because query cost and the amount of bytes billed are directly proportional.
It is important to note that the metadata tables are independent from Stackdriver logs. This implies that data such as IP addresses and device information is not available. They are a series of tables natively available in BigQuery. And they do not require Stackdriver logs to be exported to BigQuery.
Metadata in INFORMATION_SCHEMA.JOBS_BY_PROJECT
The following information is available in the BigQuery job metadata table, as described in Google’s documentation here:
| Column name | Data type | Value |
| creation_time | TIMESTAMP | (Partitioning column) Creation time of this job. Partitioning is also based on the UTC time of this timestamp. |
| project_id | STRING | (Clustering column) ID of the project. |
| project_number | INTEGER | Number of the project. |
| folder_numbers | RECORD | Google Accounts and ID Administration (GAIA) IDs of folders in a project’s ancestry. The order starts with the leaf folder closest to the project. This column is only populated in JOBS_BY_FOLDER. |
| user_email | STRING | (Clustering column) Email address or service account of the user who ran the job. |
| job_id | STRING | ID of the job. For example, bquxjob_1234. |
| job_type | STRING | The type of the job. Can be QUERY, LOAD, EXTRACT, COPY, or null. Job type null indicates an internal job, such as script job statement evaluation or materialized view refresh. |
| statement_type | STRING | If valid, the type of query statement, such as SELECT, INSERT, UPDATE, or DELETE. |
| priority | STRING | The priority of this job. |
| start_time | TIMESTAMP | Start time of this job. |
| end_time | TIMESTAMP | End time of this job. |
| query | STRING | SQL query text. Note: The JOBS_BY_ORGANIZATION view does not have the query column. |
| state | STRING | Running state of the job. Valid states include PENDING, RUNNING, and DONE. |
| reservation_id | STRING | Name of the primary reservation assigned to this job, if applicable. Also, if your job ran in a project that is assigned to a reservation, it would follow this format: reservation-admin-project:reservation-location. reservation-name. |
| total_bytes_processed | INTEGER | Total bytes processed by the job. |
| total_slot_ms | INTEGER | Slot-milliseconds for the job over its entire duration. |
| error_result | RECORD | Details of error (if any) as an ErrorProto. |
| cache_hit | BOOLEAN | Was the query results of this job from a cache? |
| destination_table | RECORD | The destination table shows the results (if any). |
| referenced_tables | RECORD | An array of tables referenced by the job. |
| labels | RECORD | An array of labels applied to the job as key and value strings. |
| timeline | RECORD | Query the timeline of the job. Contains snapshots of query execution. |
| job_stages | RECORD | Query stages of the job. |
| total_bytes_billed | INTEGER | total bytes billed by the job. |
Note that the folder_numbers column is not applicable to the JOBS_BY_PROJECT table, as described in the relevant “value” column of the table above.
IAM
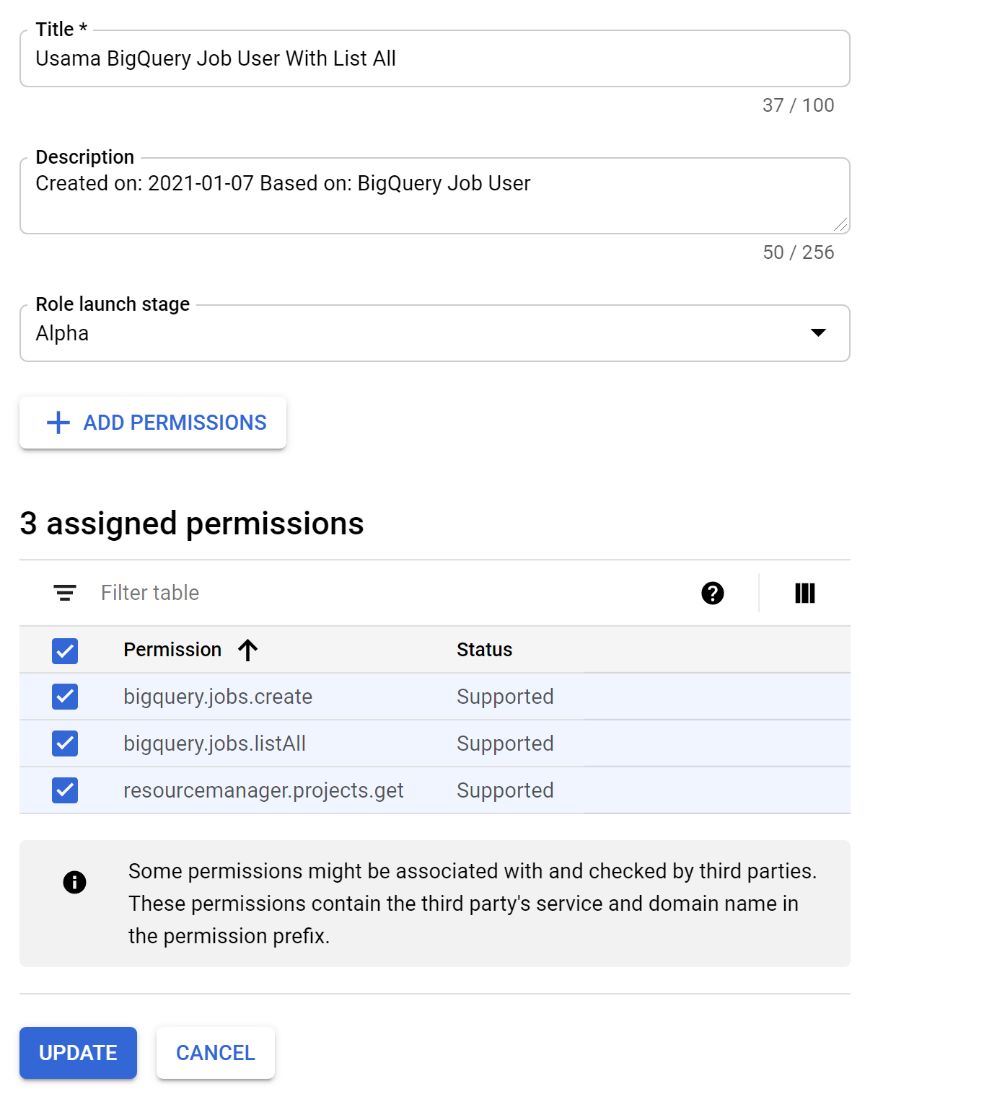
The minimum roles and permissions required to query JOBS_BY_PROJECT are the following:
- jobs.listAll
- roles/bigquery.jobUser (includes bigquery.jobs.create, resourcemanager.projects.get, resourcemanager.projects.list)
Details about these IAM permissions can be found in Google’s documentation here.
These permissions do not give ‘view’ or ‘write access’ to existing user datasets. Instead, their jobs.listAll permission gives access to project-level job history. While jobUser allows the firing of queries only on the tables accessible to the users. In this case, jobs.listAll exposes the JOBS_BY_PROJECT metadata table. So, together these permissions allow queries to be fired on that table.
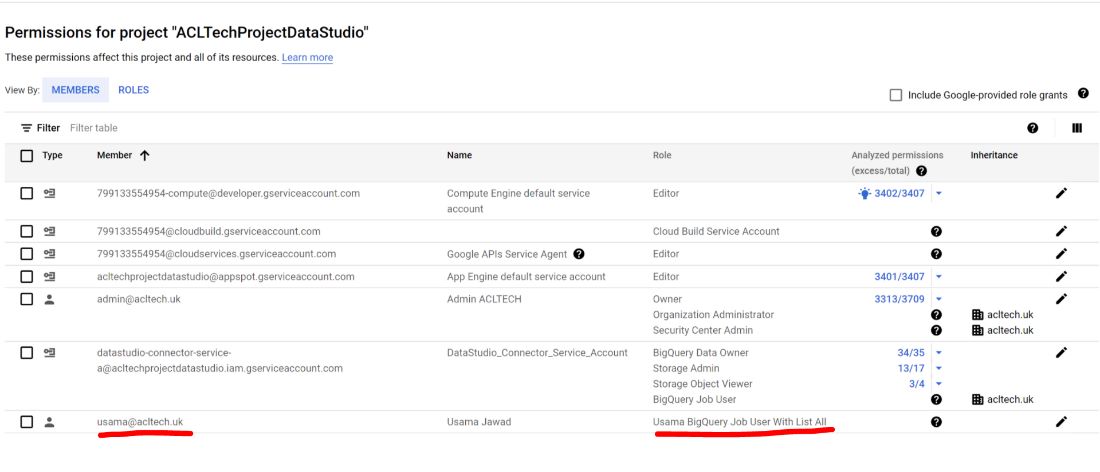
IAM in Demo Project
Only the minimum permissions described in the “IAM” section were applied to a user in a project, as can be seen below:
Query in the Demo Project
The following query is executed which fetches all the data from the job history metadata table. It also displays the top 5 results in order of bytes billed (cost). This is a slight modification of the query described in Google’s documentation here.
SELECT
*
FROM `region-europe-west2`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
ORDER BY total_bytes_processed DESC
LIMIT 5
Users can modify this query to have a calculated column such that ‘total_bytes_processed’ is first converted to TBs. They can then multiply this by the region’s per-TB cost.
As can be seen in the screenshot, other existing datasets in this project are not visible to the user firing the query:
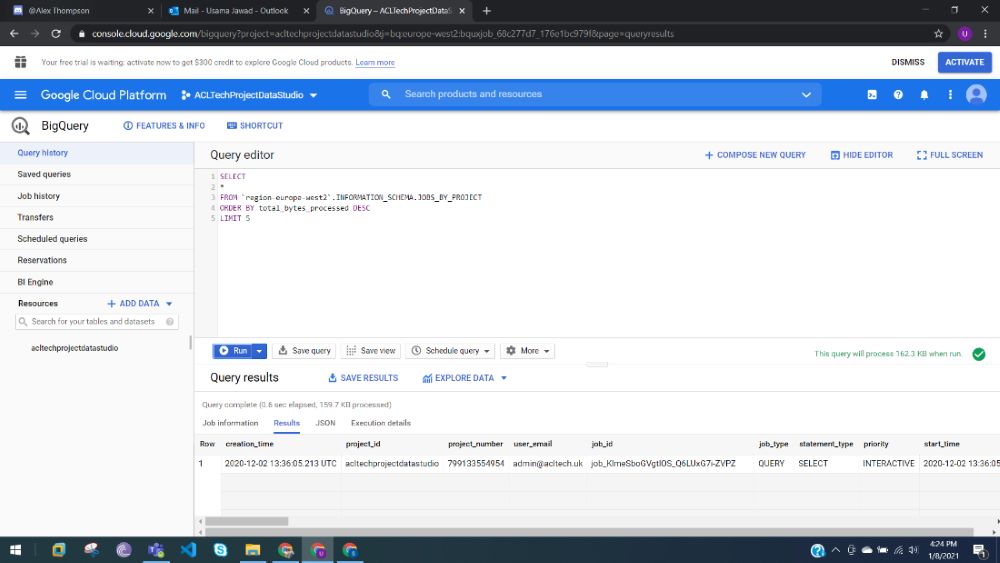
The INFORMATION_SCHEMA.JOBS_BY_PROJECT table is qualified with the region. The example above shows query history in Europe-West2, but it can be modified to “region-us” to get the metadata from the US.
This query can also be further optimized to get only relevant columns. Because of this, users can reduce query costs and build further operational dashboards or views.
Conclusion
GCP does not offer this level of granularity by default. Because of this, users find it nearly impossible to determine the source of BigQuery pricing costs and their remedy. In such cases, the metadata tables available natively in BigQuery can be extremely useful. They show exactly which user triggered the query and the time they triggered it. Users can also learn about the exact query itself and the cost of running that query.
Remarkably, the fine-grained permissions available in GCP BigQuery ensure that queries can be confined to operational and admin teams. This is because they can only use it to monitor costs on GCP BigQuery. Users also are not able to view or query other existing data.
