
AI agents are great tools for intelligent automation. You can make any business operation veritably faster and better with them. But only if agents are trained using clean, consistent data. Otherwise, things can go south very quickly.
Therefore, data quality management is necessary to build promising agents that actually get the work done. Data quality for AI even takes into account things that are usually of low priority in traditional data quality management.
So, you can’t overstate the importance of good quality data in agentic AI solutions.
And in this blog, we’ll discuss exactly why that is and what ‘good quality’ actually means in an agentic context.
Why AI agents need data quality management
Thanks to Silicon Valley tech bros, people have this misconception that AI agents think on their own. Yes, it is very possible they might do so in the coming years. But for now, agents calculate probabilities to take any action based on the data they are fed.
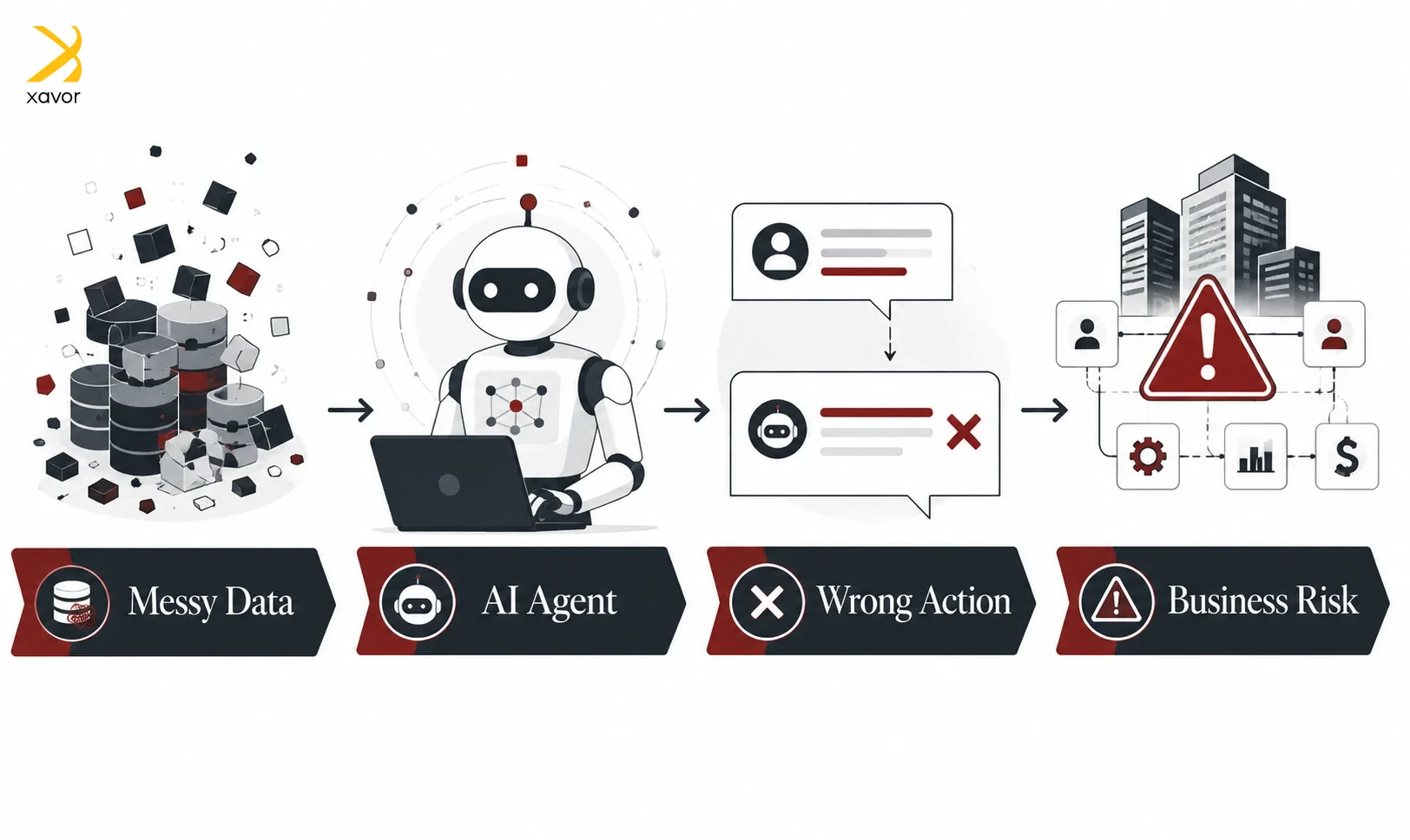
And if that data is messy or spotty, the agent will churn out unpredictable responses to say the least. McDonald’s rolled back its AI drive-thru experiment for this reason. The system misinterpreted one customer’s request to place an order for a bacon-topped ice cream.
The customer said, “One vanilla ice cream cone,” and the agent calculated it as bacon. McDonald’s was fortunate that this mistake was mostly comical. But it again highlighted a major reason why a lot of enterprise AI projects never make it. Poor data quality management turns agents into liabilities like above.
Other strands of AI are also prone to this limitation. Generative AI systems also hallucinate to give you faulty information if the data behind them is inaccurate.
It’s just the way AI is at the moment. Machine learning models power all types of AI systems. And these models learn whatever datasets they are given without any inference of their own. So, they reflect all the faults or biases of the data they are trained on.
So, does AI agent data needs to be perfect?
Data quality management aims for perfection. But most companies don’t have perfect data, and probably never will. And that is perfectly fine. Agentic AI can still create value from imperfect data with a little bit of workaround.
Better data will always produce better results. However, it doesn’t mean you wait for perfect data to start. Clunky data is often still usable, especially when AI agents are used repeatedly and continuously.
What makes quality AI data?
We said this in the intro that data quality management for AI is more stringent. Therefore, we’ll first look into good-quality AI data from a general perspective. And then the specific peculiarities that are important in the case of AI data quality management.
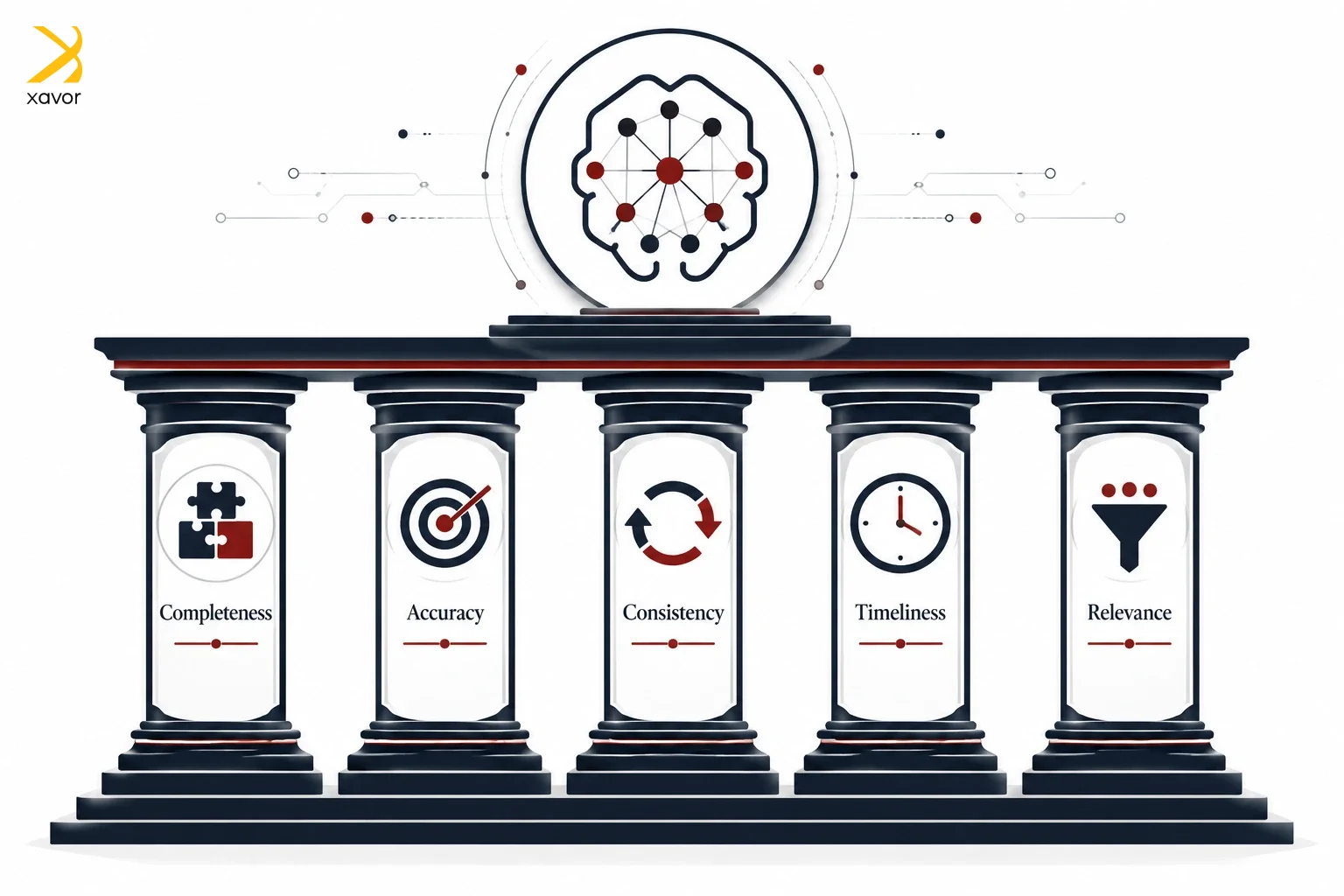
Traditionally, data quality comes down to five things:
- Completeness
- Accuracy
- Consistency
- Timely
- Relevance
Completeness
Completeness is necessary to ensure that nothing important is missing in the agent’s dataset. And completeness starts with integration. Enterprise AI systems mostly fail because business context is scattered across platforms and operational workflows.
That is why we engineer AI systems to retrieve context across the enterprise instead of reasoning from fragmented visibility.
Accuracy
You need accuracy to prevent the agent from saying or doing incorrect things. Hallucinating agents are especially a liability in customer-facing workflows, like in the above case of McDonald’s.
Accuracy in enterprise AI is not achieved through larger models alone. It comes from governed retrieval and authoritative source systems. Xavor prioritizes source-of-truth architectures, so agents retrieve validated data instead of relying on spurious or doubtful information.
Consistency
Sometimes, agents can contradict their own decisions over time. For example, one customer should not receive a different policy interpretation than another simply because the AI retrieved data from document versions. Consistency prevents that.
We address this issue in our internal agentic solutions through centralized policy orchestration. Each of our enterprise workflows is synchronized, so AI agents behave consistently across departments.
Timely
Timely means that the dataset is updated to stay in touch with reality. And business realities change very quickly. Something happens in one part of the world, and it has ripple effects on a company on the other side of the globe.
That is why AI agents operating on outdated information quickly become liabilities. Xavor engineers real-time synchronization and observability pipelines so agents stay aligned with operational reality instead of static snapshots frozen in time.
Relevance
Last but not least, relevance means that the data is actually useful for an agent to do its tasks. Giving an agent more and more data can increase hallucinations. That is why we design an AI architecture that retrieves only context relevant to the task and operational scope of the agent.
Remember that in enterprise AI, precision matters more than volume.
AI-focused data quality management dimensions
Traditional systems follow rules you write. But AI agents infer rules from data. That’s why the following data quality factors are specifically pertinent in AI.
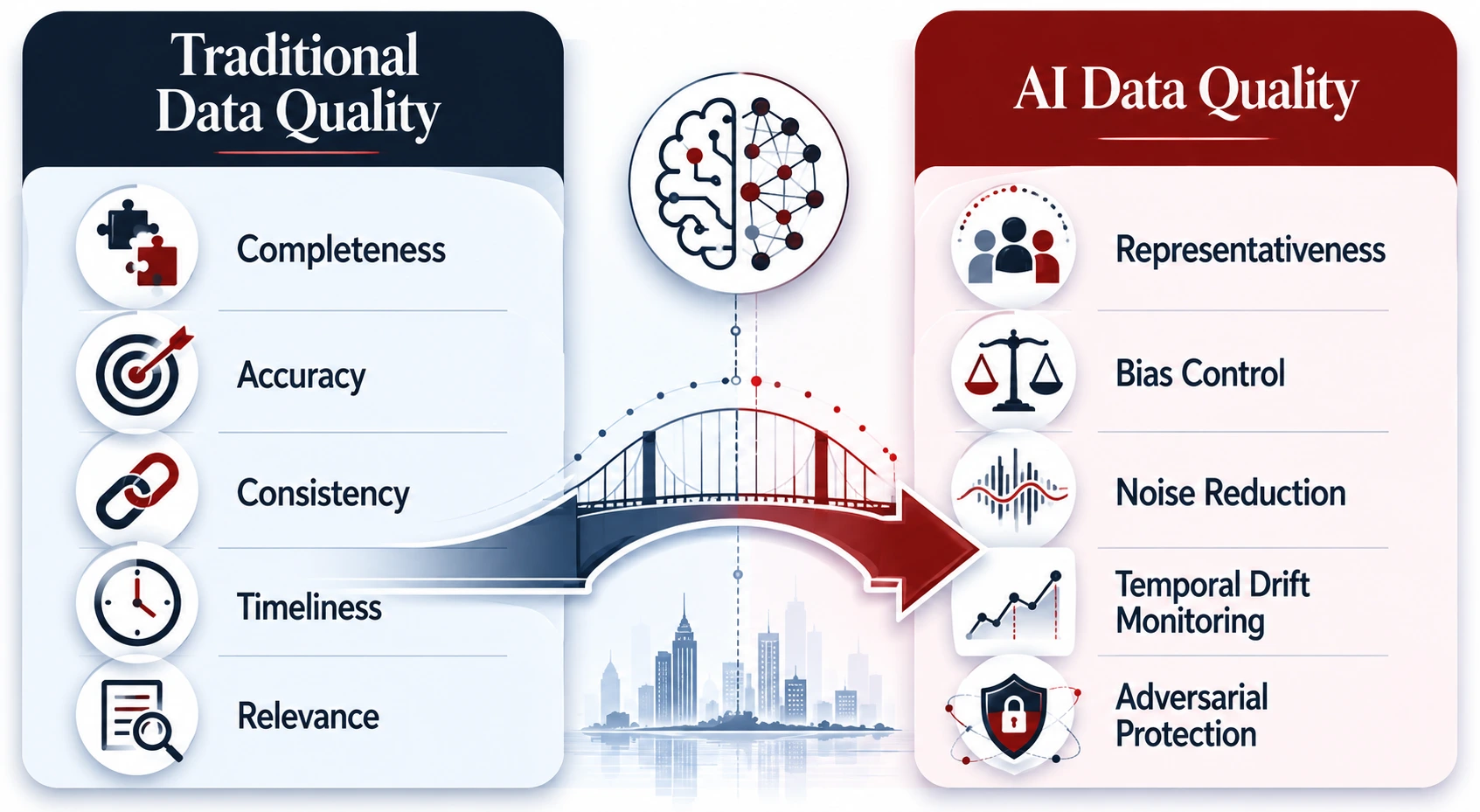
Representativeness
A model’s training data must reflect the real world. Otherwise, it will never know what it’s missing. It will just be confidently wrong for every case that wasn’t in the training set. For example, physical AI systems are mostly trained on synthetic data. But that data is created to mimic real-world spatial awareness and physical laws as is.
Our eldercare physical AI robot, Navi, operates in real-world environments with real humans. So, we made sure its training data faithfully represented real-world spatial dynamics and physical variability.
Bias
Humans create AI. And we have biases. Modern LLMs can inherit those biases in their training. So, quality data in the case of AI means it is free from any kind of biased or discriminatory information, like racial stereotypes.
In the regulated industries like healthcare we work in, biased AI outputs carry detrimental legal and reputational consequences. That is why we run bias audits across demographic slices and build diverse review teams into the labeling process.
Noise
Noise removal in AI data quality management is an engineering task. At least that’s how we see it. Automated anomaly detection at ingestion helps us strip irrelevant variables before training.
And it is vital because data quality management for AI agents needs to be free of irrelevant variations. They can genuinely confuse a model trying to find patterns. One company’s model once learned that ice cream sales predict drowning because both spike in summer.
Temporal drift
AI models can drift away from accuracy over time. It is called model drift when data that was accurate when the model was trained may no longer reflect reality. The model doesn’t know time has passed, so it’s your job to keep it informed.
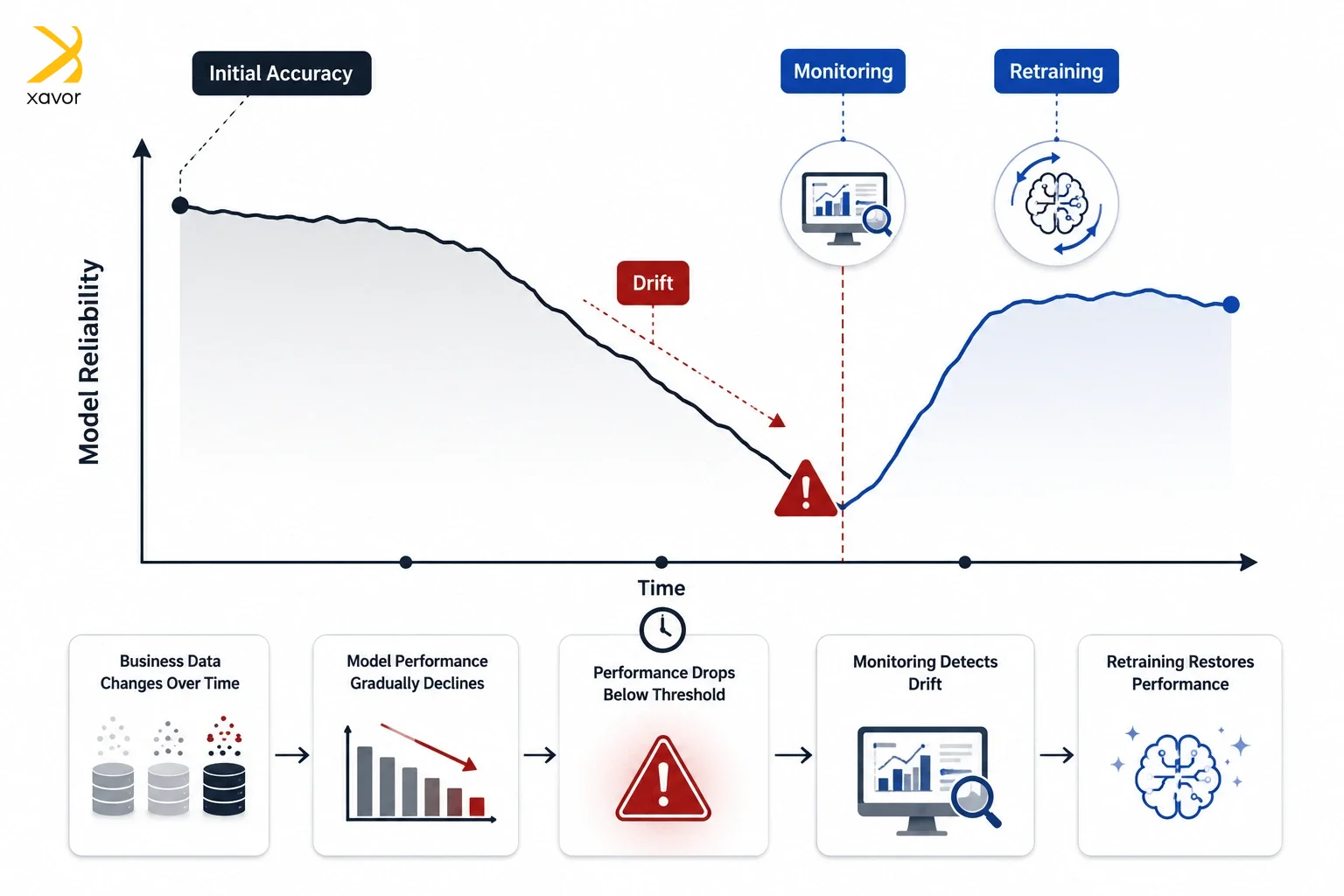
We’ve seen these wreck production systems in ways that are genuinely difficult to diagnose. So, our AI experts deploy continuous drift monitoring to catch the moment the model’s understanding of the world starts diverging from the world itself.
Adversarial vulnerability
AI models can be deliberately misled by subtly manipulated inputs in ways traditional systems simply aren’t. Prompt injections are a great example of that. That is why AI data quality requires inputs that are validated and monitored for manipulation before they ever reach the model.
The best way of dodging these attacks is to ensure the agent can only act within the boundaries it was authorized to operate in.
Moreover, if you want a more advanced solution, you can try dual model sandboxing. It works for us like a charm regardless of what an agent has been told by external inputs.
The role of continuous governance in AI data quality management
Good quality data doesn’t maintain itself. Its quality has to be governed continuously once AI agents are deployed. That is why you need ongoing AI governance processes to keep your enterprise data in mint condition.
Start with accountability. Assign dataset owners who are responsible for what’s in the data. We have stewards, you can say, who manage the company’s AI datasets day-to-day. Furthermore, a governance council is now part of many organizations. It sets policy and resolves conflicts when they arise.
Then build clear policies around the basics:
- How data gets entered
- How long has it been retained
- How frequently is it updated
- Who can access it, and how privacy requirements are met
Furthermore, new data sources are always entering a growing AI ecosystem. But never let them flow directly into production. Run quality assessments and document everything first. One unvetted data source can quietly corrupt an agent’s reasoning across an entire workflow.
Our AI governance squads also version-control schemas and quality rules the same way we version code. It gives us an audit trail to maintain a clear record of what changed and when. So, keep that in your governance checklist as well.
It is also essential to conduct regular quality reviews with stakeholders across the business. The people closest to operations often catch what dashboards miss.
Finally, train every team that touches AI data to imbibe that their inputs become the model’s reality. Data quality management is an organizational discipline that holds only when everyone understands what’s at stake.
Conclusion
Charles Babbage quotes an anecdote that he was asked on two occasions whether a machine can give the right answer if it is given wrong figures. “I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question,” was his reaction.
Babbage understood the concept of Garbage In, Garbage Out centuries before it became a thing in computing. A machine cannot magically correct bad inputs. Yes, even AI isn’t there yet to automatically determine whether the data it is fed is true and reliable.
Modern AI systems often appear intelligent enough to overcome bad data. But they really need data quality management to actually do it and produce reliable outputs.
Contact us at [email protected] to learn about our data quality management solutions. We can sort out your messy data with proper governance and orchestration to make it AI-ready.

FAQs
AI agents make decisions and take actions based on the data they receive. Poor-quality data can lead to hallucinations, inconsistent responses, biased outputs, and operational failures, especially in enterprise environments.
Yes, but only to a point. Modern AI agents can reason through incomplete or messy data better than traditional systems, but they still need governed, accurate, and timely information to remain reliable and trustworthy.
The biggest risks include stale data, inconsistent information across systems, biased datasets, prompt injection attacks, and model drift over time. These issues can cause AI agents to make incorrect or unsafe decisions at scale.