
Data engineering is crucial for making impactful AI products a reality. Nearly every headline AI capability depends on pipelines that can collect, clean, and serve data across many systems and formats. ChatGPT, Sora, Gemini, and the likes all require huge swathes of high-quality data to create that one line of code or the image that you give them prompts to generate.
But this has also increased the pressure on data teams to convert messy or poorly defined data into AI-ready data. That’s why data engineering solutions have become a foundational, make-or-break layer for AI readiness. An AI data engineer turns raw information into timely, well-structured inputs that models can learn from and operate on.
This blog will explore in detail the inseparable link between AI and data engineering. How data engineering helps in AI projects deployments, some real-world use cases to elaborate on it. And the final sections will discuss some common data engineering challenges, along with some best practices
What is data engineering?
Data engineering is the behind-the-scenes discipline that makes data usable for analytics and AI systems. It focuses on designing and operating the systems that collect raw data from many sources, store it efficiently, and transform it so that people and LLMs can use it.

In practice, data engineer solutions build a “data factory.” They create data models, build pipelines, and enforce quality so data stays accurate and accessible for decision-making and machine learning. Organizations seek data engineering consulting because, without clean data and smooth flow across formats and platforms, even the best AI models struggle to deliver real value.
The link between AI and data engineering
Any AI solution is only as good as the data it learns from and runs on. If the data it trains on is trash, the AI will churn out trash output. You might be thinking trash is a strong word, but that’s what the industry actually calls poor quality data. Garbage In, Garbage Out (GIGO) is the concept that flawed, biased, or poor quality information or input produces a result or output of similar quality.
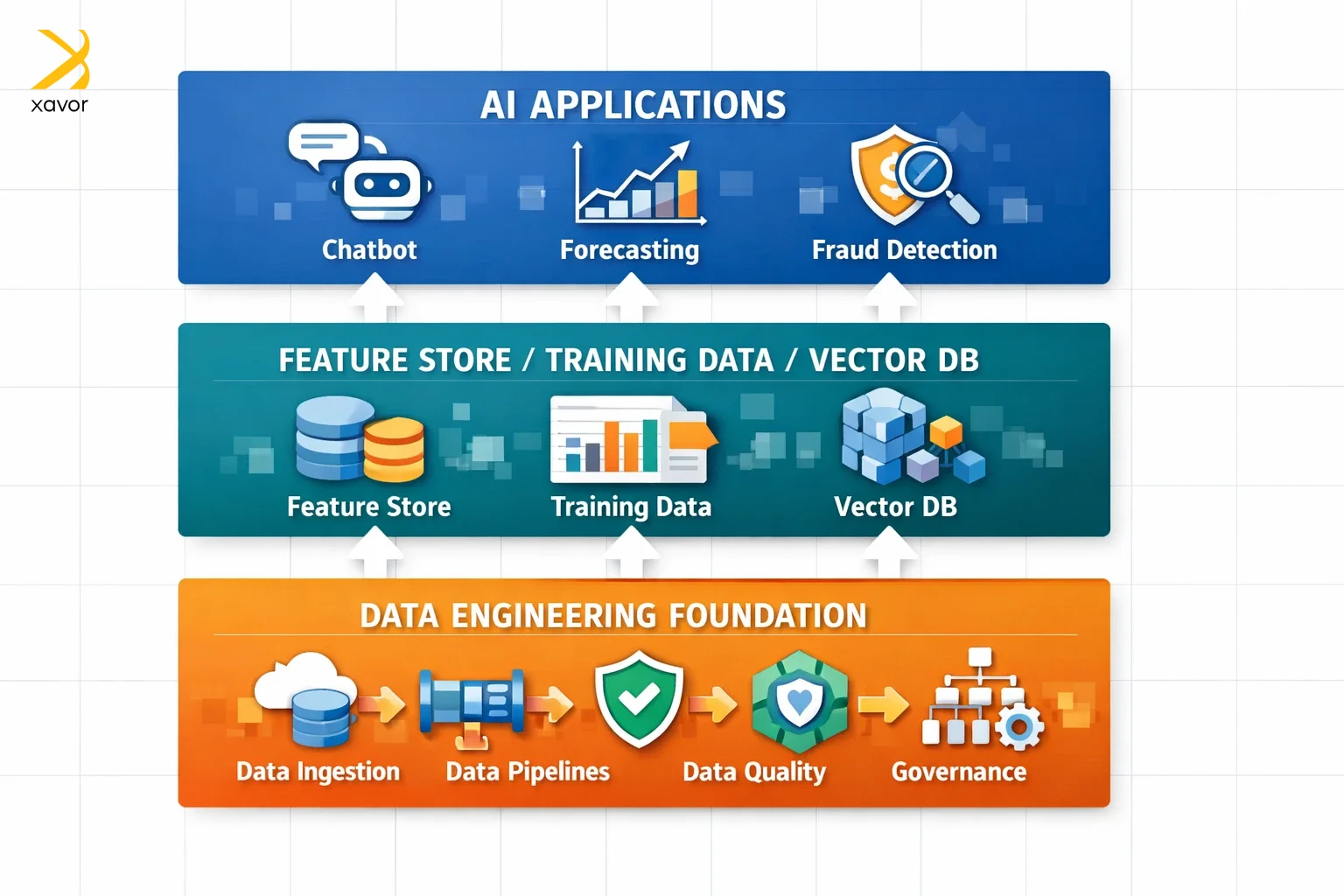
The data engineering lifecycle involves collecting data from different sources, cleaning and transforming it, and then structuring it so that machine learning models can actually use it. Moreover, data engineering tools also handle the operational side, which involves making sure data is well-managed, updated, and easy to access.
This work is becoming even more critical with the growth of AI technologies. Models and AI products can quickly drive massive increases in data volume and complexity, so data engineers design scalable pipelines and architecture that move large amounts of data smoothly across source systems. And at the enterprise level, this same foundation includes data governance and quality frameworks that keep data accurate and consistent.
5 ways data engineering solutions help in AI adaption
There are several ways data engineering solutions make AI adoption simpler and more effective. Here are some of those real-world, tangible ways data engineering tools and leading data engineering platforms make that possible:
1. Data acquisition
Data acquisition is like getting the raw materials in AI deployments. Data engineers pull data from many places, such as:
- Internal databases
- Third-party APIs,
- IoT devices or web sources
Bringing data from disparate sources into the company’s data platform in a consistent way is difficult since it’s not just copying data. Data engineers have also made sure that what they collect is reliable, complete, and usable. If this step is weak, AI models train on gaps and produce unreliable predictions.
For example, a retailer wants an AI model to forecast product demand and reduce stockouts. Retail data engineering in this case would require data pipeline development that acquires data from multiple sources. Once acquired and validated, the retailer has a solid foundation for the AI model. Therefore, demand forecasts reflect real behaviour across stores and channels, not messy or missing inputs.
2. Data processing
Collecting data is just the start. The next step in designing data engineering solutions is data processing. It is the step where data engineers repair and standardize the data so models can learn from it correctly.
That usually includes:
- Fixing errors and purging corrupted records
- Removing repetitions
- Normalizing formats and IDs
Data processing leads to more accurate models and more trustworthy AI outputs.
3. Data transformation
After data is cleaned, it still often isn’t in a shape that AI models can learn from. Data transformation is the step where data engineers reshape and enrich the data so it becomes model-ready and more informative.
Data engineering solutions convert raw data into usable structures that a model can consume. Afterwards, data engineers build meaningful signals so the model learns patterns more easily.
Finally, detailed events are summarized into higher-level patterns, like weekly averages, customer lifetime value, or total returns per customer, so the model sees the bigger picture.
4. Data integration
Data is everywhere these days. You have modern cloud applications, IoT devices, and big systems like ERP, all generating tons of data. If data engineering solutions stay separated like this, AI is limited in how accurate or useful its insights can be.
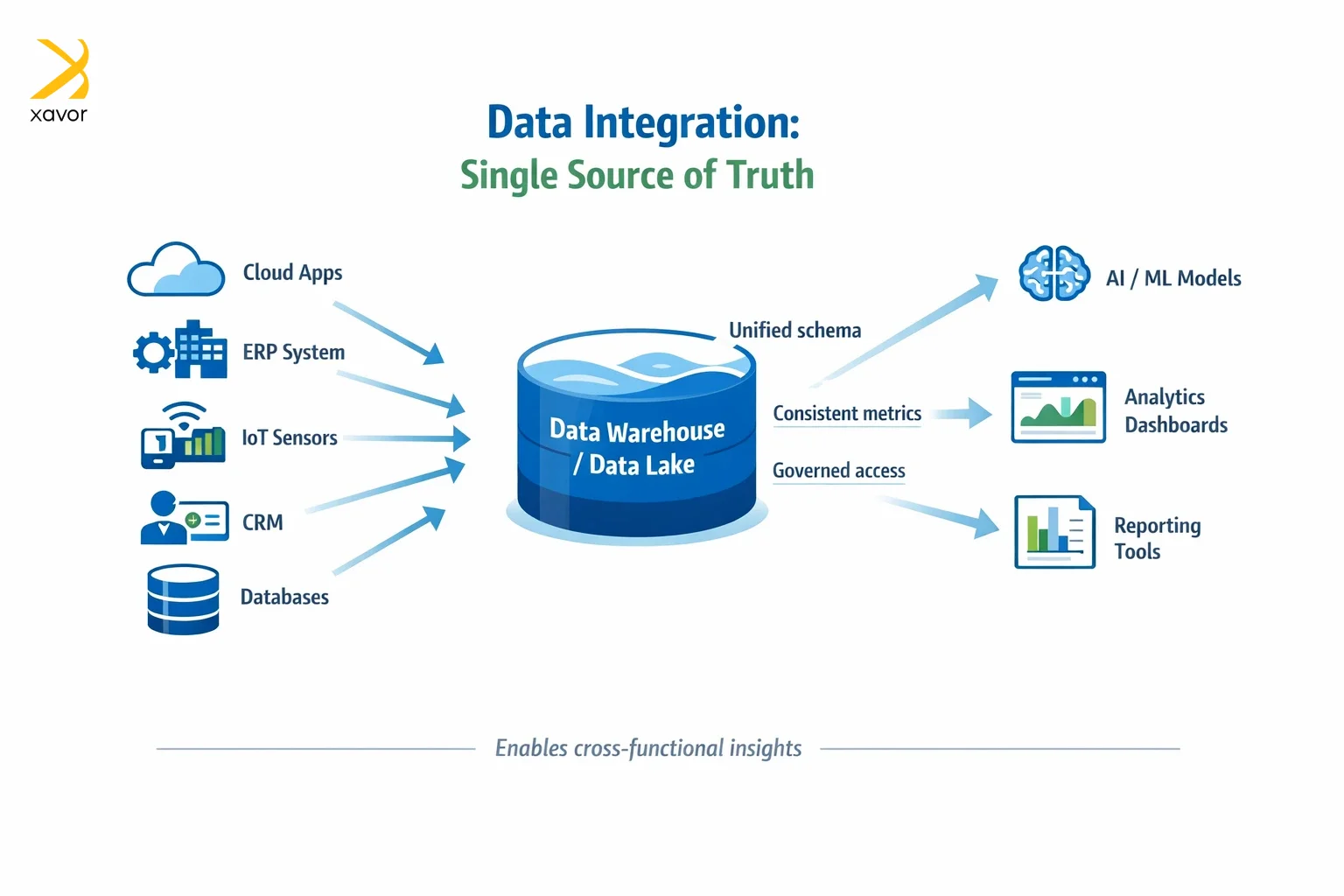
That is why modern data engineering solutions resolve this by bringing all those sources together into a single, scalable data platform. Usually, that platform is a Data warehouse or data lake.
The goal is a “single source of truth”, which is a consistent, trusted view of the business that everyone can rely on. Once data is integrated, AI can find patterns across the whole organization. For example, it can connect supply chain delays with sales drops, or link customer feedback with product performance and returns.
5. Data security
All data is confidential, but some data is more confidential than others. When companies use data, they must protect it and follow privacy laws, such as
- GDPR
- HIPPA
- CCPA
If they don’t, they risk legal penalties and loss of customer trust. Data engineering solutions build security and governance directly into the data systems that feed AI systems. Encryption, audit trails, and access control are different methods that all serve the same purpose: safe and responsible use of data.
Real-world use cases of data engineering AI
Below are some practical examples of how data engineering solutions take AI projects a step closer to reality.
1. Retrieval-augmented generation (RAG)
RAG systems allow LLMs to retrieve relevant information before generating answers, so don’t rely only on what a model “remembers.” They work by retrieving relevant information from your data and documents at query time, then using the model to generate an answer grounded in that information.
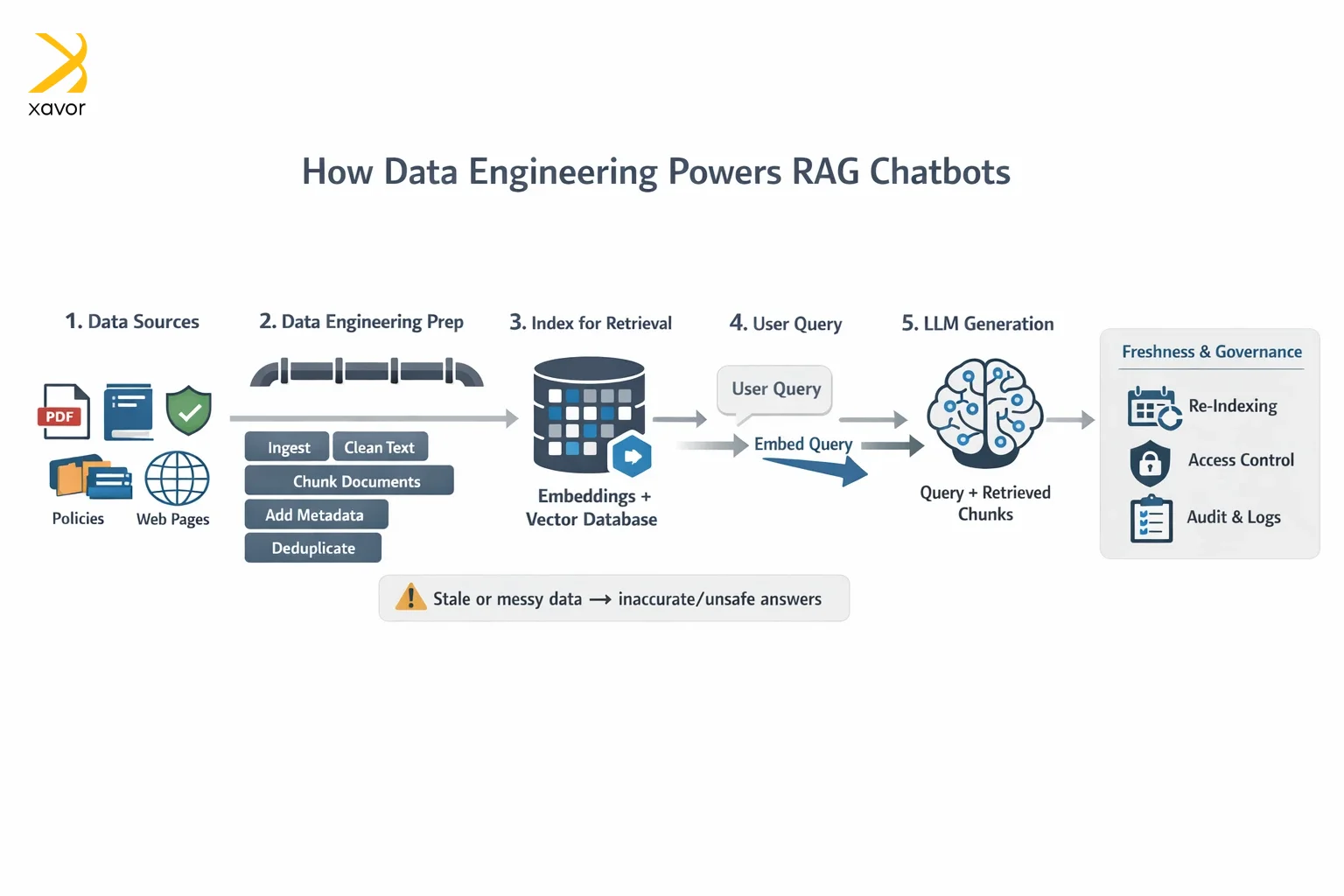
Data engineering solutions are critical in RAG because engineers aggregate and organize enterprise data into usable repositories. Furthermore, they prepare data for search and retrieval, often by chunking documents, cleaning text, and storing it in systems that support retrieval.
Keeping data fresh is also important, so the chatbot doesn’t answer using outdated policies or old product information.
A RAG chatbot is only as good as the information it can reliably retrieve. Without strong data pipeline development, it becomes inaccurate and even unsafe to use.
2. AutoML platforms
AutoML platforms help teams build, deploy, and monitor ML models faster by automating parts of model training, tuning, and sometimes model selection. But these platforms still depend on a steady stream of correct data.
Data engineering solutions enable AutoML with data pipeline development that regularly delivers new data so models can be retrained or refreshed. Such systems also rely on data processing to capture signals that reveal model health. Operational stability is non-negotiable, too. Since data jobs need to run on time, dependencies are managed, and failures are fixed quickly.
AutoML can speed up model creation, but without solid data pipelines, “self-optimizing” models can still degrade. Data engineering solutions keep AutoML effective in real production environments.
3. Metadata management
Metadata is basically “data about the data.” It includes definitions, ownership, lineage, classifications, and other data minutiae. Humans need it to work with data confidently. AI systems also benefit because metadata provides the meaning and constraints behind datasets.
Data engineering solutions support this by building or integrating data catalogs. What are data catalogs? They explain what datasets exist, what they mean, and who owns them.
This data engineering use case ensures models are trained on the right datasets, and teams can understand limitations and reduce misuse. In short, data management turns data from a pile of tables into something interpretable.
Data engineering tools Xavor employs for AI enablement
The selection of the right kind of data engineering tools is the first step in data engineering AI. We have worked on several data engineering solutions for different industry clients. Therefore, our data engineers know that each situation requires a different tool set.
But there are some of the most important data engineering tools that we routinely employ and recommend to you for AI enablement.
| Tool | Category | How it enables AI |
| Apache Kafka | Data streaming/ingestion | Enables real-time data ingestion from applications and events so AI models can make timely predictions |
| Snowflake | Cloud data warehouse | Supports scalable feature extraction and model training data pulls with strong access control |
| Databricks | Lakehouse platform | Combines data lakes and warehouses for large-scale data processing |
| Airflow | Workflow orchestration | Schedules and monitors data pipelines that feed AI models |
| Informatica | ETL /data integration | Connects many enterprise sources and delivers curated datasets for training |
| Amazon Redshift | Cloud data warehouse | Provides a centralized store for structured analytics/ML datasets and supports consistent data access patterns |
| Looker | BI/semantic layer | Creates consistent business definitions that help AI models train on correct measures |
Biggest data engineering challenges for AI
Xavor has been working in the data industry for decades, and we’ve seen many challenges come and go. And in our experience, these are some of the biggest data engineering challenges impeding AI enablement for organizations.
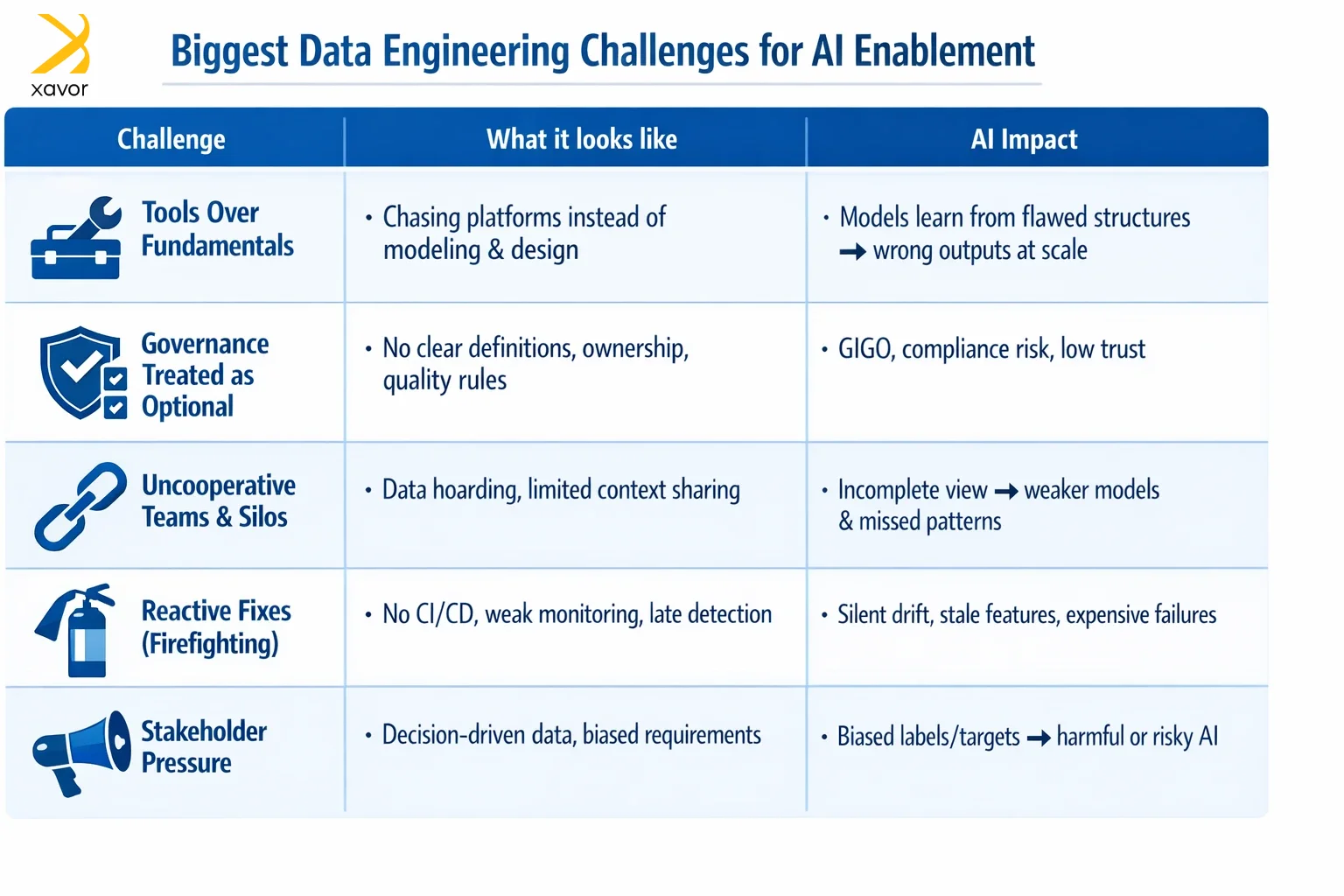
1. Tools over fundamentals
A lot of companies have the wrong priorities when it comes to data engineering AI. They obsess over tools like they are some silver bullets. Databricks, Redshift, and Snowflake are excellent platforms, but they won’t do everything in creating data engineering solutions for AI.
First priority should be the fundamentals of the data engineering lifecycle. Once you are clear about data modeling, system design, and access patterns, then you can start thinking about which tools to use. You can’t “tool your way” out of unclear definitions and poorly designed tables. These mistakes will reflect in your AI models on an X10 scale.
2. Considering data governance unimportant
This one we can’t understand because decades of institutional knowledge emphasize the importance of data governance. But for some reason, this insight has been lost as many modern organizations treat data governance and quality as second-class work.
Companies push for speedy data pipeline development, while governance and quality control are neglected until something breaks. Therefore, design your data engineering solutions with governance in mind if you don’t want your AI model to make errors and mistakes.
3. Uncooperative teams
Not every challenge is technical. It has been noted that different teams in an organization tend to hoard data and don’t share context. Now, we don’t know if this recalcitrant attitude is due to office politics or if there are genuine concerns about losing ownership.
Either way, this attitude needs to go because you can’t build reliable AI tools if cross-team data sharing and ownership aren’t solved socially as well as technically.
4. Reactive fixes
Internal data engineering teams are often busy putting out daily fires. Due to this reactive approach, they sometimes neglect basic data engineering foundations, like CI/CD and traceability.
But AI and data engineering can’t afford this dereliction of duty. AI systems rely on continuous, fresh data. If a pipeline slows down or starts producing subtly wrong values, models can drift over time without anyone noticing. And by the time the problem is discovered, the damage is done.
5. Stakeholder pressure
Business leaders often want data that supports what they already believe. However, data is objective, and you can’t distort the data to present a picture you want. This stakeholder pressure leads teams to mold data engineering solutions that meet the requirements.
For AI enablement, that’s a major risk because it can produce questionable training targets and incentives to ignore edge cases. This can be embarrassing at least, and legal trouble at worst.
Data engineering best practices for AI enablement
If you’re making AI data engineering solutions, your personal work choices will also directly affect the model’s accuracy.
We find these data engineering best practices a good starting point for AI projects. Following them will help you create AI data engineering solutions that deliver long-term reliability.
1. Work with data scientists
Consider AI and data engineering as a team sport. AI projects succeed when data engineers and data scientists work closely from the start. Data engineers can deliver clean and structured datasets for training and inference. Afterwards, data scientists can give feedback on whether the data is relevant and useful for the modeling approach.
Both teams working together can spot problems early and refine features, which will reduce expensive fixes later. Otherwise, there is no point in creating data engineering solutions that nobody can use.
2. Use data contracts
Data contracts are basically agreements between the teams that produce data and the teams that consume it. Since systems like APIs and databases can change over time, AI pipelines need to change as well if you don’t want them to break.
Using data contracts in data engineering solutions prevents this by clearly defining what the data producer must deliver, such as:
- Schema:
- Quality rules
- SLAs
- Versioning and change rules
This way, you can keep the training and inference data stable and predictable, so models don’t get surprised by upstream changes.
3. Keep learning new methods
AI and data engineering are evolving quickly. Staying current with the latest methods and tools is part of the job. It is very important to create modern data engineering solutions that are built for the AI age.
For example, new patterns like RAG pipelines already have their own set of best practices. Therefore, join communities, learn from mentors, enroll in courses, and do anything that helps you in continuous professional development.
The role of AI in data engineering
This might seem to be going off the tangent, but we want to end the blog with another important link between AI and data engineering. The relationship between them goes both ways: data engineering solutions affect AI enablement, and AI is affecting data engineering itself as well.
In this piece, we only discussed the former. Maybe in another article, we’ll break down the latter relationship with equal depth. But for now, remember that AI in data engineering is making notable changes.
AI is helping fix a common issue in data engineering solutions. ETL work is often bespoke. Different engineers use different tools and patterns for each request. Each pipeline might work fine on its own, but collectively this creates a messy, hard-to-manage ecosystem. This risk grows with AI agents, as they may start generating pipelines automatically, each with its own code and approach.
Therefore, data engineering solutions can now be built with a declarative approach. Instead of hand-building pipelines from scratch, data engineers can describe what they want in natural language, and AI helps generate the pipeline implementation.
Conclusion
AI and data are part and parcel of each other. The ability to use data properly for enterprise-wide AI deployments rests squarely on data engineering. However, what’s often overlooked is that data engineering can actively shape what AI can and cannot do.
The quality of decisions an AI system makes, the trust users place in its outputs, and the speed at which it adapts to change are all reflections of the data pipelines beneath it. Xavor’s data engineering solutions are designed to turn AI ambitions into real-world projects. Our data engineering consultants help you design production-ready data pipelines, which build the foundation for your AI to succeed.
Partner with Xavor today to strengthen your data backbone. Contact us today at [email protected] to book a discovery call.

FAQs
No, data engineering isn’t being replaced by AI. AI can automate parts of the work, but enterprises still need data engineers to design architecture, ensure data quality and governance, manage security/compliance, and run reliable pipelines at scale.
AI and data engineering are tightly linked because AI is only as good as the data it learns from. Data engineering collects, cleans, integrates, and delivers reliable data through pipelines and governance, so AI models can train accurately, stay up to date, and run safely at scale.
Data engineering builds and maintains the data foundation, like pipelines, storage, models, and governance. On the other hand, data science uses that data to analyze, experiment, and build predictive/ML models to generate insights and drive decisions.