
The word plumber comes from the Latin word for the metal lead, plumbum. Romans used water pipes made from lead, so people who dealt with pipes were called plumbers. What does it have to do with this blog? Well, data engineering is not that different from plumbing. But instead of water, data engineers manage the flow of data.
ETL pipelines are the equivalent of plumbing pipes and fittings. They move data from multiple resources into a place where you can analyze it. Just like a leaky pipe can become a real problem in your house, ETL pipelines need to be robust and stable to handle millions of pieces of information.
In this blog, we’ll explain how you can build and integrate ETL pipelines on a cloud data platform using modern cloud services and the best tools.
What are ETL pipelines?
ETL (Extract, Transform, Load) is a data integration process that pulls data from different systems, cleans and standardizes it, and then delivers it into a central place where it can be analyzed, such as:
- Data warehouse
- Data lake
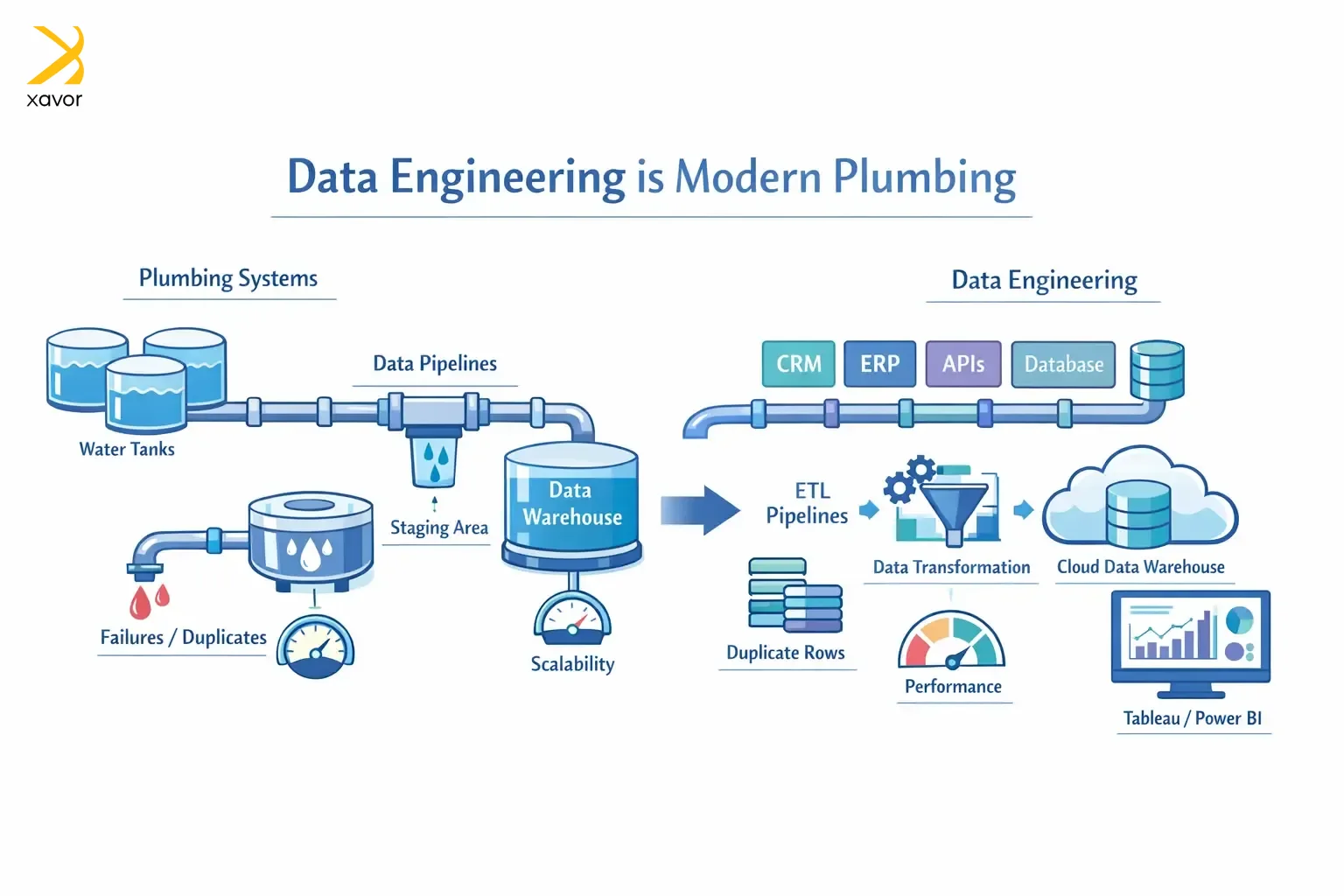
A company’s different departments may generate data in their own formats, so the same thing can look different everywhere. If you leave it scattered, you end up with duplicates, inconsistencies, and confusion.
ETL pipelines act like a reliable delivery-and-cleanup system: it gathers the data, fixes errors and mismatches, combines related pieces, and loads it into one trusted source so the team can use it confidently without constantly second-guessing what’s correct.
The ETL process
The three phases of an ETL pipeline: extract, transform, and load. Let’s take a look at each of them.
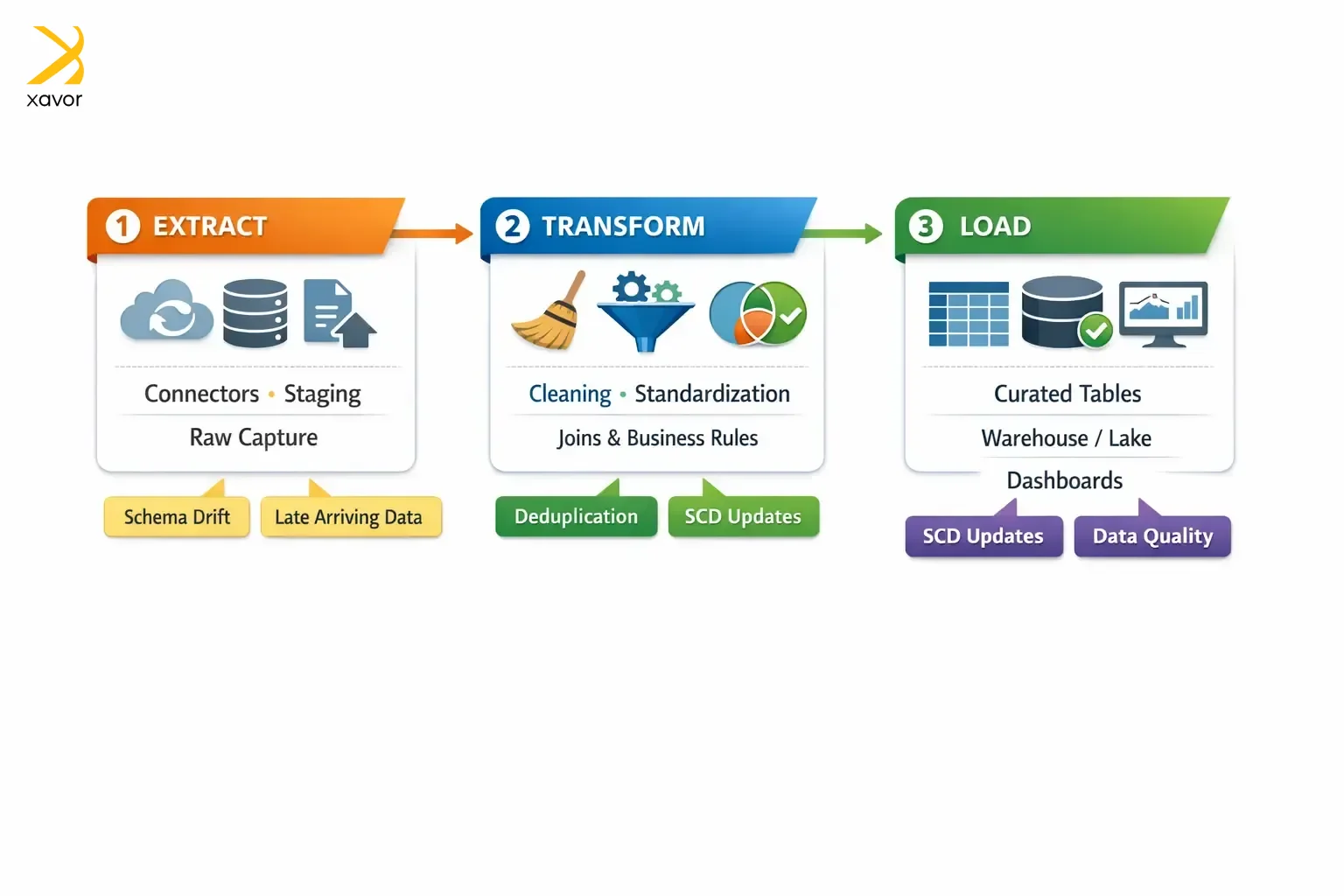
1. Extract
Extract is the step where data is first taken out of the places where it originally lives. Data ingestion pulls raw, untouched data from source systems like databases, cloud tools, files, or APIs.
At this stage, you’re just collecting what’s there as accurately as possible. That raw data is usually dropped into a temporary staging area, so it’s safely captured before any cleaning or transforming starts.
2. Transform
The extracted data then needs cleaning and organization. ETL pipelines clean and turn data into a format that is ready for data analysis. This is also where data stops being just a copy and becomes something you can confidently use.
3. Load
Lastly, the cleaned or processed data is delivered to its destination. And it is usually data warehouses, data lakes, or cloud data platforms. You can also run the organized data on a BI tool like Tableau or Power BI.
Loading the data is what finally generates reports and insights through analysis, which are used for decision-making.
Common ETL pipeline development tools
These ETL tools are your wrenches and bolts to make stable ETL pipelines. We’ve categorized these tools by what of the pipeline they help with.
| ETL Function | Tools |
| Orchestration | Apache Airflow, Dagster, AWS Step Functions, Azure Data Factory |
| Extraction | Fivetran, Airbyte, Meltano, Stitch |
| Transformation | dbt, Apache Spark, Databricks |
| Streaming | Apache Kafka, AWS Kinesis, Azure Event Hubs |
| Integration | Talend, Informatica, AWS Glue |
| Quality and testing | Soda, dbt tests, Great Expectations |
| Monitoring | Monte Carlo, Bigeye, Datadog |
Cloud data engineering steps to build stable ETL pipelines
Data engineering and cloud computing have increasingly intertwined. Many businesses have shifted to cloud platforms like Azure, AWS, and Google Cloud. So, data engineers have to do the same work for cloud-native environments.
Cloud data engineering is almost the same as regular data engineering. But there are a few particularities of the cloud, such as infrastructure-as-code (IaC), that come into play.
Using the steps below, you should be able to create a strong, stable ETL pipeline for any cloud data platform. When evaluating tooling for this process, exploring fivetran competitors for multi-cloud data synchronization can help teams find solutions that better align with their scalability, flexibility, and cost requirements across different cloud environments, as alternatives like Airbyte or Hevo often offer customizable deployment and pricing models.
1. Make idempotency #1 priority
ETL jobs often face issues like network hiccups, timeouts, and worker crashes. They have to retry whenever there is a failure, which is why idempotency is very important. Yes, it sounds like a scholarly term, but idempotency simply means you can run the same operation multiple times and the end result is the same as running it once.
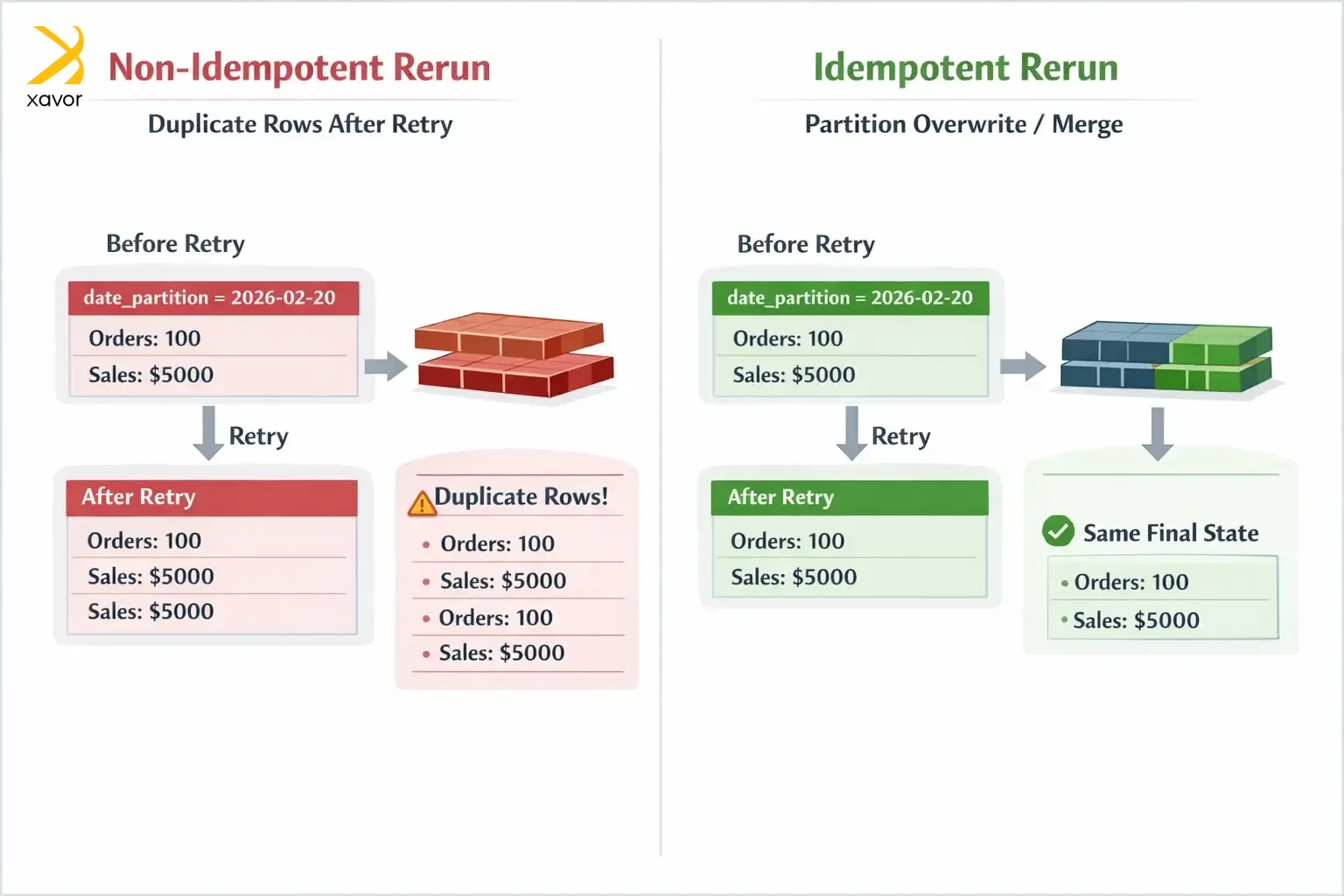
That’s the core trait of ETL pipelines you can trust. Without idempotency, a rerun after a failure might append the same data again, creating duplicates and forcing someone to manually clean things up. With idempotency, you just rerun the job, and it safely lands in the same correct state.
The most common approach to achieving idempotency is to overwrite a known slice of data instead of always appending. For example, if your table is partitioned by day, then each run for a specific day should replace that day’s partition.
Because the delete and insert happen together, rerunning the same date doesn’t add more rows. It replaces the day’s results, so the outcome stays the same every time.
2. Use incremental loads
ETL pipelines tend to start small, and then the data grows… and grows… and suddenly your simple nightly job is grinding through millions of rows every run. That’s where incremental loading is necessary. Incremental loads mean you only process what’s new or what changed, instead of reprocessing everything every time.
A full refresh is the brute-force approach, where you delete or rebuild the whole table on every run. It’s straightforward, but it’s also expensive, slow, and creates many challenges for data engineering and AI deployment. The bigger your dataset gets, the longer it takes, the more it costs, and the more likely it is to fail halfway through. And when it fails, you’ve wasted a lot of compute and time for nothing.
Incremental loads flip the mindset. The pipeline keeps track of what it has already processed, usually via a timestamp, a high-water mark, or change data capture. And then asks: “What happened since my last successful run?” That makes jobs faster, cheaper, and easier to run more frequently.
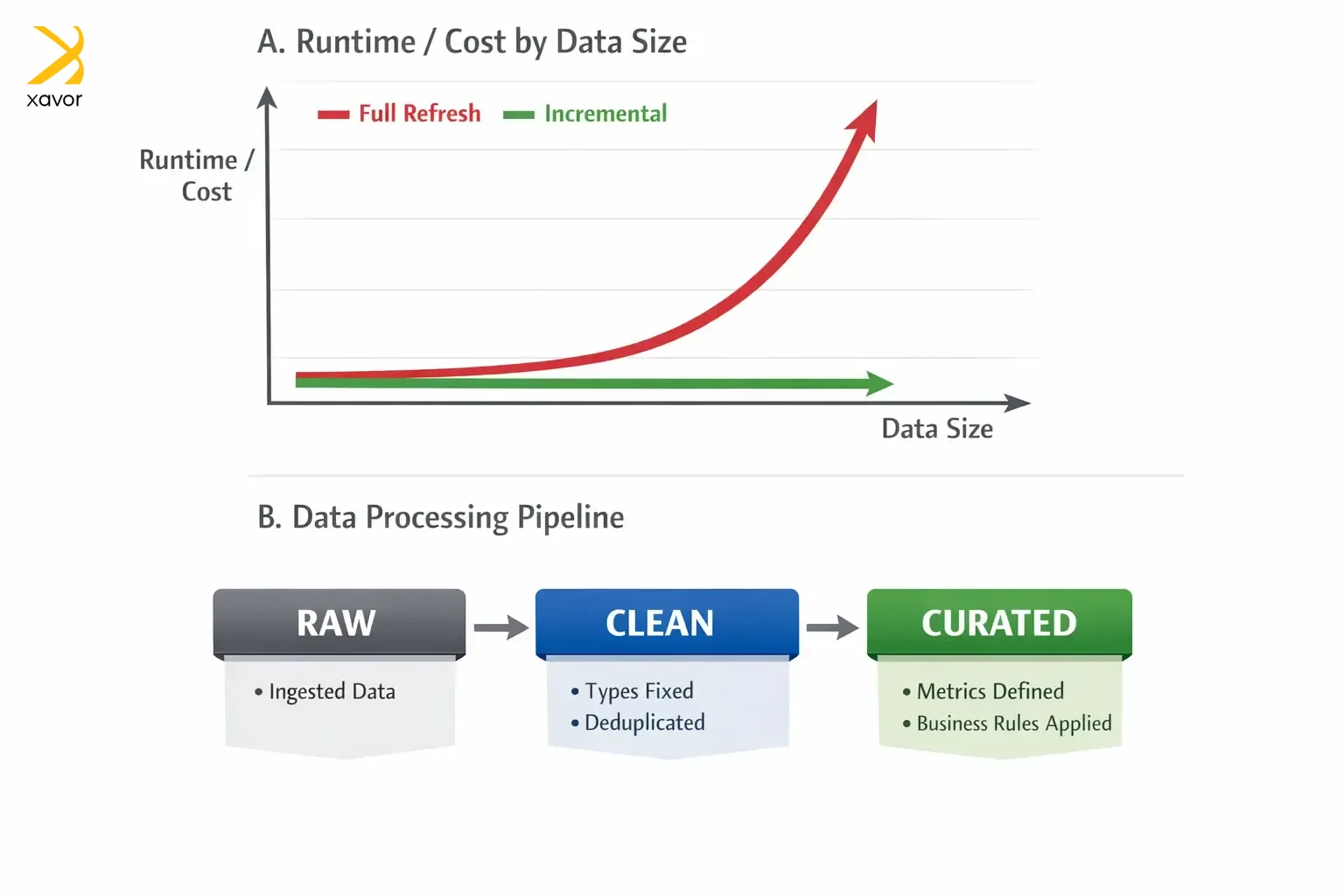
Incremental logic has to be careful. Data can arrive late, records can be updated after the fact, and systems can backfill. That’s why many production pipelines reprocess a small recent window to catch late changes, and they pair incremental loads with idempotent writes, so reruns don’t create duplicates.
3. Implement a layered architecture
One of the fastest ways for an ETL setup to become unmanageable is when everything gets mixed together. Raw source data, business rules, and dashboard-ready metrics are all tangled in the same place. It might work for a while, but the moment something looks off, nobody can tell where the problem came from. This leads to unstable, unreliable ETL pipelines.
A layered architecture prevents chaos by giving your data an organized path from messy to trustworthy. The basic idea is to store the same data in stages, where each stage has a clear purpose.
The first layer is raw, which is an accurate copy of what the source gave you. No fixes, no assumptions, no business logic. This layer is your ground truth for debugging and auditing. If a report looks wrong, you can always go back and prove what the source actually sent.
Next is the clean layer, where you standardize and repair things. You fix types, normalize timestamps, standardize names, deduplicate records, and apply consistent structure. It’s still not business metrics, but it’s now stable, comparable, and safe to build on.
Finally, you have the curated layer where business meaning lives. You apply definitions like net revenue, active user, or churn, and you create the tables that dashboards and stakeholders depend on. A layered architecture is basically the difference between stable ETL pipelines that are easy to operate and one that becomes a mystery box.
4. Treat it as software engineering
A lot of ETL pipelines start as just a script. Someone writes a quick job, it works, and suddenly that script is powering decisions across the company. However, that’s the trap because data pipelines feel informal at first, but they become production systems. Production systems need an engineering discipline.
If you don’t treat ETL pipelines like software, you end up with fragile jobs that only one person understands, and nobody wants to touch. Your core mindset is that pipelines should be repeatable, reviewable, and deployable. That means keeping them in version control, so every change is tracked and reversible. It also means doing code reviews, so logic isn’t sneaking into production without another set of eyes. Additionally, it means writing tests to catch breakages before stakeholders do.
Finally, you need to use CI/CD, so changes are deployed in a consistent way, not by copying and pasting code into a server at midnight. And in cloud data engineering, it means IaC. As a result, your permissions, storage, schedules, and compute aren’t hand-configured mysteries that drift over time. If you can’t recreate your environment from code, you don’t really control it.
Conclusion
Stable ETL pipelines build a trust system. When your reporting is fast and reliable, teams stop debating whose numbers are right and start using data to make decisions with confidence. But when pipelines are fragile, people build workarounds, keep shadow spreadsheets, and slowly drift away from the very platform that was supposed to unify everything.
Your data platform becomes your company’s nervous system. If signals arrive late, inconsistent, or duplicated, the organization makes worse decisions while thinking it’s being data-driven. That’s why the goal is to build a system that can handle real-world messiness.
So, here are some useful questions to leave you with: if your most important dashboard was wrong today, how quickly would you know? And how confidently could you trace the problem to its source? The answer is a pretty good indicator of whether your pipelines are just running or truly reliable.
Partner with Xavor’s cloud data warehouse engineering services to build ETL pipelines that scale cleanly on AWS, Azure, or Google Cloud. Get in touch today at [email protected] to architect, modernize, and harden your pipelines into a platform your business can trust.

FAQs
An ETL pipeline is an automated workflow that extracts data from different sources, cleans and standardizes it, and then loads it into a central system like a data warehouse or lake. This makes the data reliable and ready for reporting, dashboards, and analysis.
ETL pipelines can be built with tools like Apache Airflow, Fivetran/Airbyte, and dbt/Spark, often loading into warehouses like BigQuery, Snowflake, or Redshift. The best tool depends on your data sources, scale, and whether you need batch or real-time processing.
Common types of ETL pipelines include batch pipelines that run on a schedule, real-time or streaming pipelines process data continuously, incremental pipelines load only new or changed data, and full-refresh pipelines rebuild everything each run.