
Artificial intelligence is moving into a new phase where the main constraint is not model access, but Data readiness for AI inside the enterprise. For years, most deployed AI looked like reactive tools: search that retrieves information or chatbots that answer direct questions. These systems can help, but they usually stay inside a fixed flow and do not rely heavily on real enterprise data across many systems.
Now the focus is shifting to agentic AI, where a system receives an objective and completes work through multiple steps using enterprise data and approved tools, which makes enterprise data management a core requirement. Many organizations use Agentic AI Development Services to define agent workflows, tool permissions, and data access rules that match business controls. An agent can draft a customer’s response or prepare a compliance summary, but these outcomes depend on data readiness for AI. When enterprise data is inconsistent or outdated, the agent may respond quickly while the result stays hard to trust.
That is why the $93B question matters: organizations can fund AI capacity, but results depend on whether enterprise data management is ready for agents that operate across systems. Data readiness is the difference between an agent that produces a traceable, policy-compliant output and an agent that spreads conflicting records, outdated documents, or sensitive fields into the wrong place. This guide focuses on the practical indicators of readiness and the enterprise data management steps that make agentic AI safe and dependable.
The numbers that show what’s coming
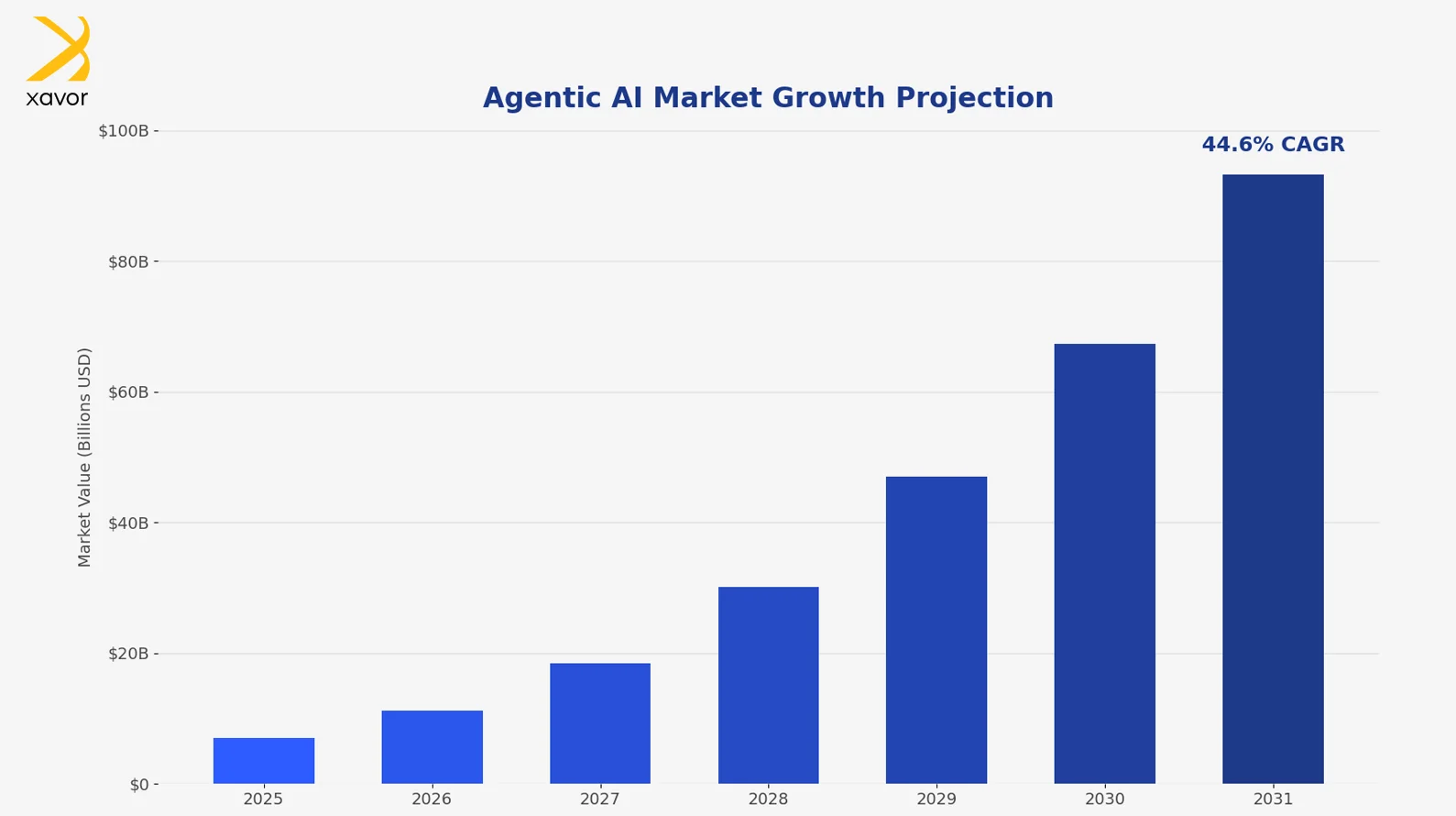
Agentic AI is shaping up to be a major economic wave. Analysts expect the market to grow from around $7.06B in 2025 to roughly $93.2B by 2032, driven by a steep 44.6% CAGR. Growth at that pace signals strong demand for more capable, self-directed AI systems.
What’s powering the surge is a clear shift in business needs. Companies are moving past basic automation and looking for AI that can run complex, multi-step workflows, make real-time decisions, and operate with minimal oversight.
And in data-heavy industries like financial services, healthcare, and e-commerce, the stakes are even higher. When decisions are constant and data never stops flowing, even small efficiency gains can snowball into massive competitive advantage.
Why agentic AI raises the bar for enterprise data management
Traditional analytics often run on curated warehouse layers with scheduled refresh. Agentic AI is different because it can assemble context on the fly, blend multiple sources, and take action based on that blend. That changes what enterprise data management must guarantee.
Governance and security guidance from major frameworks consistently warn that agents increase risk when they operate without strong controls. Without proper data governance and quality, agents can introduce risk tied to sensitive data exposure, compliance boundaries, and security vulnerabilities. Risk management guidance also highlights issues that map directly to enterprise data management fundamentals: classification, access control, audit logs, and documented data quality.
So, the real question is not “Can we deploy an agent?” The question is:
Can we prove our enterprise data management controls remain intact when an agent retrieves, transforms, and uses enterprise data across systems?
Why enterprise data readiness is different for agentic AI
Many organizations believe they are prepared because they have data lakes, data warehouses, and analytics teams. These assets support reporting and forecasting, but agentic systems place different demands on enterprise data.
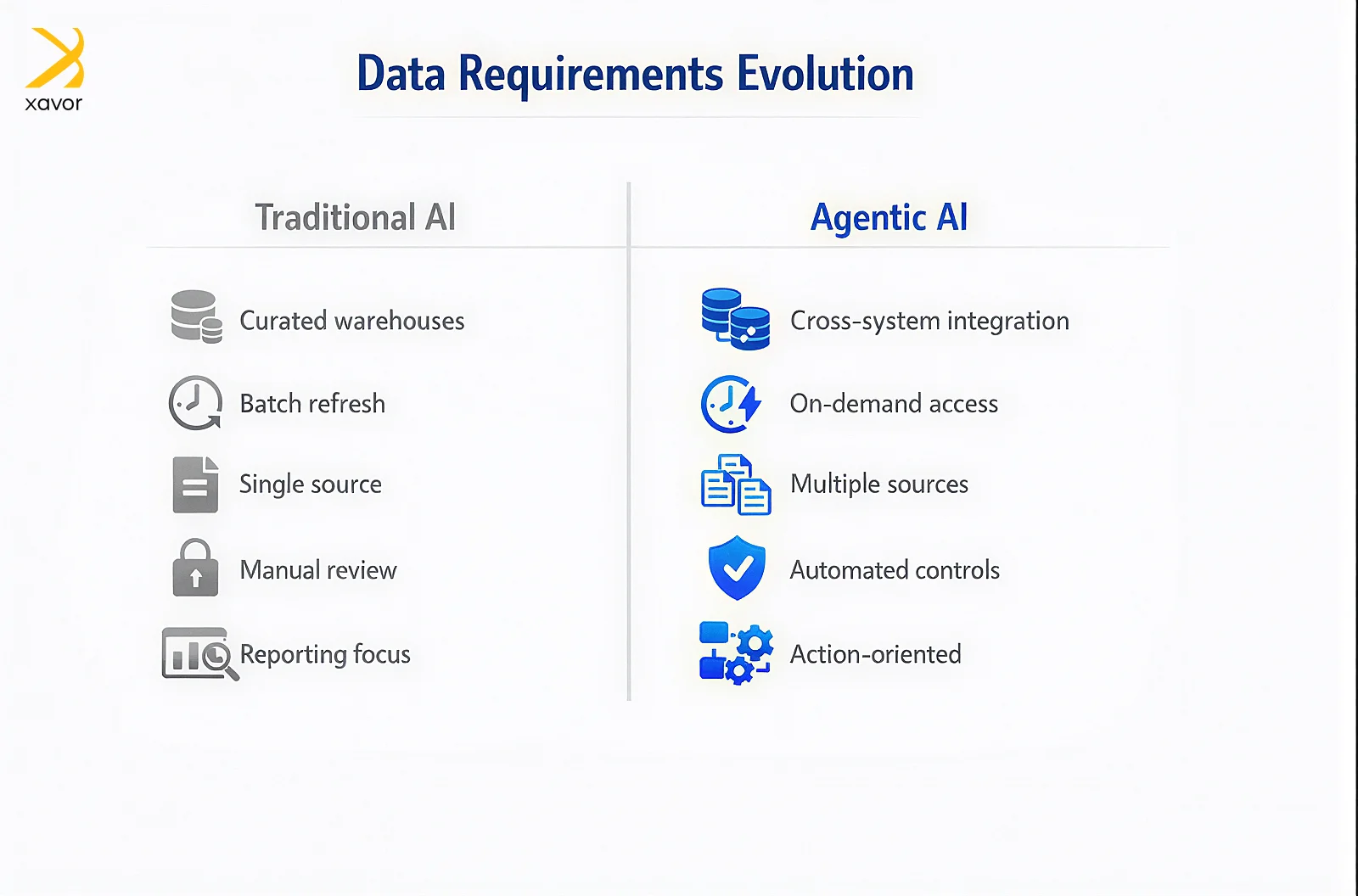
Agentic AI interacts directly with operational systems. It retrieves records, evaluates conditions, and initiates actions. This requires enterprise data that meets five conditions at the same time:
- Accuracy that supports decisions without human correction
- Consistent meaning across business units
- Context through metadata, relationships, and definitions
- Controlled access aligned to policy
- Stability as sources and rules change
Each condition exists for a practical reason. An agent that plans steps cannot stop to reconcile conflicting definitions. An agent that writes records cannot rely on undocumented assumptions. This is why data readiness is an operational requirement, not a technical preference.
The hidden gap between AI ambition and enterprise data reality
Many organizations believe they are ready for advanced AI because they have data lakes, dashboards, and analytics teams. Agentic AI exposes the limits of that assumption.
Common gaps include:
- Fragmented enterprise data across ERP, CRM, HR, supply chain, and support platforms
- Inconsistent definitions for core entities such as customer, product, vendor, and asset
- Heavy reliance on batch updates for operational decisions
- Limited visibility into where data originated and how it was processed
- Governance processes designed for reporting, not for continuous automated action
These gaps directly undermine enterprise data management in an agentic environment.
The core pillars of enterprise data readiness
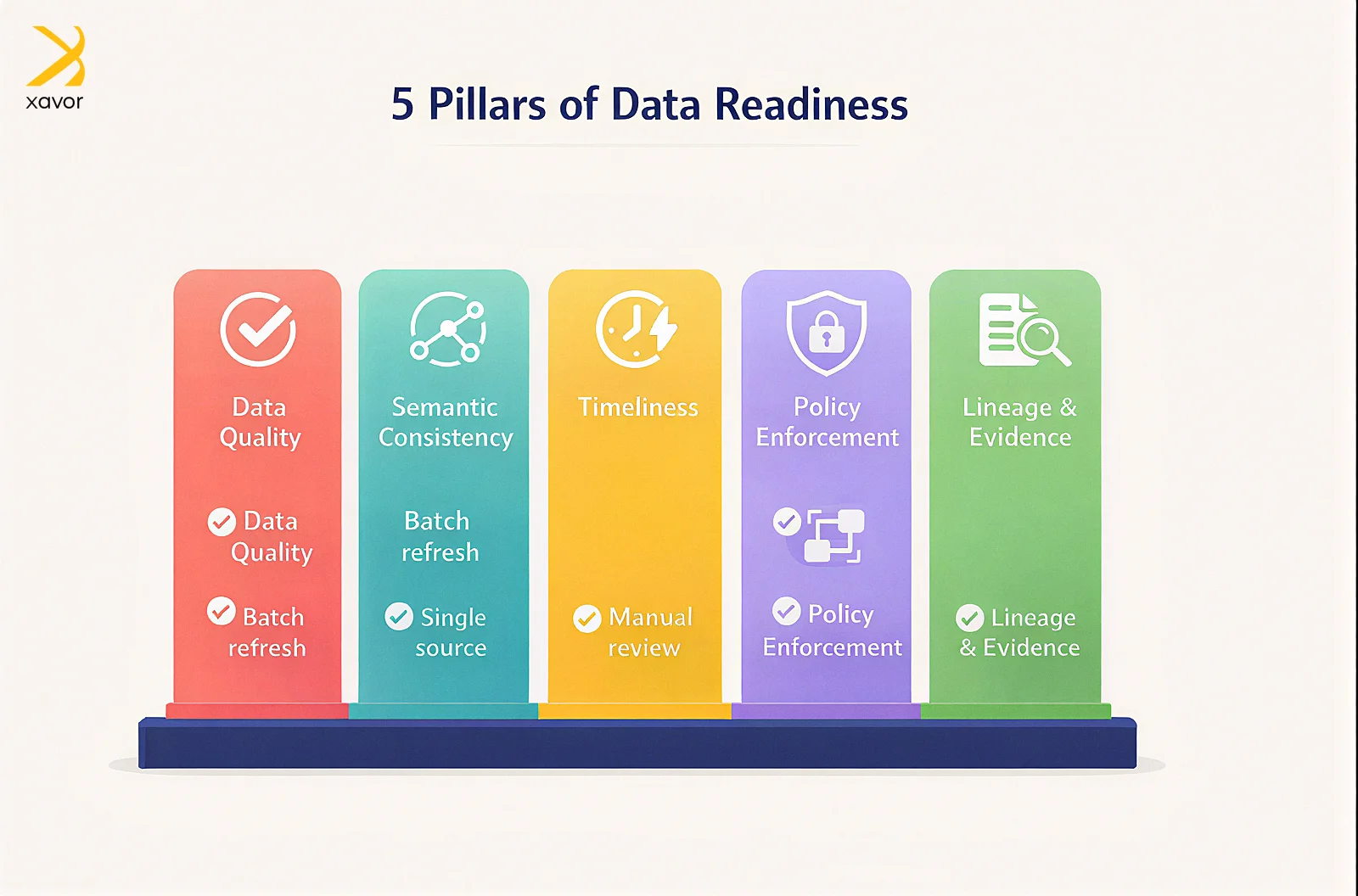
Data quality designed for action
Traditional quality programs focus on correctness for reporting. Agentic AI requires quality designed to prevent unsafe actions. For example, a purchasing agent must confirm supplier status, pricing validity, and approval thresholds before initiating an order. A customer-facing agent must confirm consent and contact accuracy before outreach.
Enterprise data management assigns ownership for these checks and ensures they run continuously, not as one-time cleanups.
Semantic consistency across enterprise data
Agents reason across systems. If definitions differ between platforms, actions conflict. Semantic consistency requires business glossaries tied to actual data fields, canonical models for key entities, and clear stewardship for change management.
This is foundational enterprise data management work, yet its importance increases sharply when AI systems act without human mediation.
Timeliness aligned to decision risk
Agentic systems depend on current state. Inventory levels, risk exposure, system health, and customer status change rapidly. Data readiness means aligning data freshness to the cost of delay. High-impact decisions require near real-time updates, while lower-risk decisions tolerate slower refresh cycles.
This alignment keeps investment focused and tied to business impact.
Policy enforcement at the data layer
Agentic AI systems require policy enforcement that operates automatically. Access controls, privacy restrictions, and usage rules must be embedded where data is stored and served. Relying on manual review does not scale when agents operate continuously.
Strong enterprise data management ensures policies are defined once and enforced consistently across use cases.
Lineage and evidence for accountability
When an agent takes an action, the organization must be able to explain why. That explanation relies on lineage that connects the action to data sources, processing steps, validation rules, and dataset versions.
Lineage supports audit requirements, internal trust, and continuous improvement. It is a non-negotiable element of data readiness.
How to assess readiness without overengineering
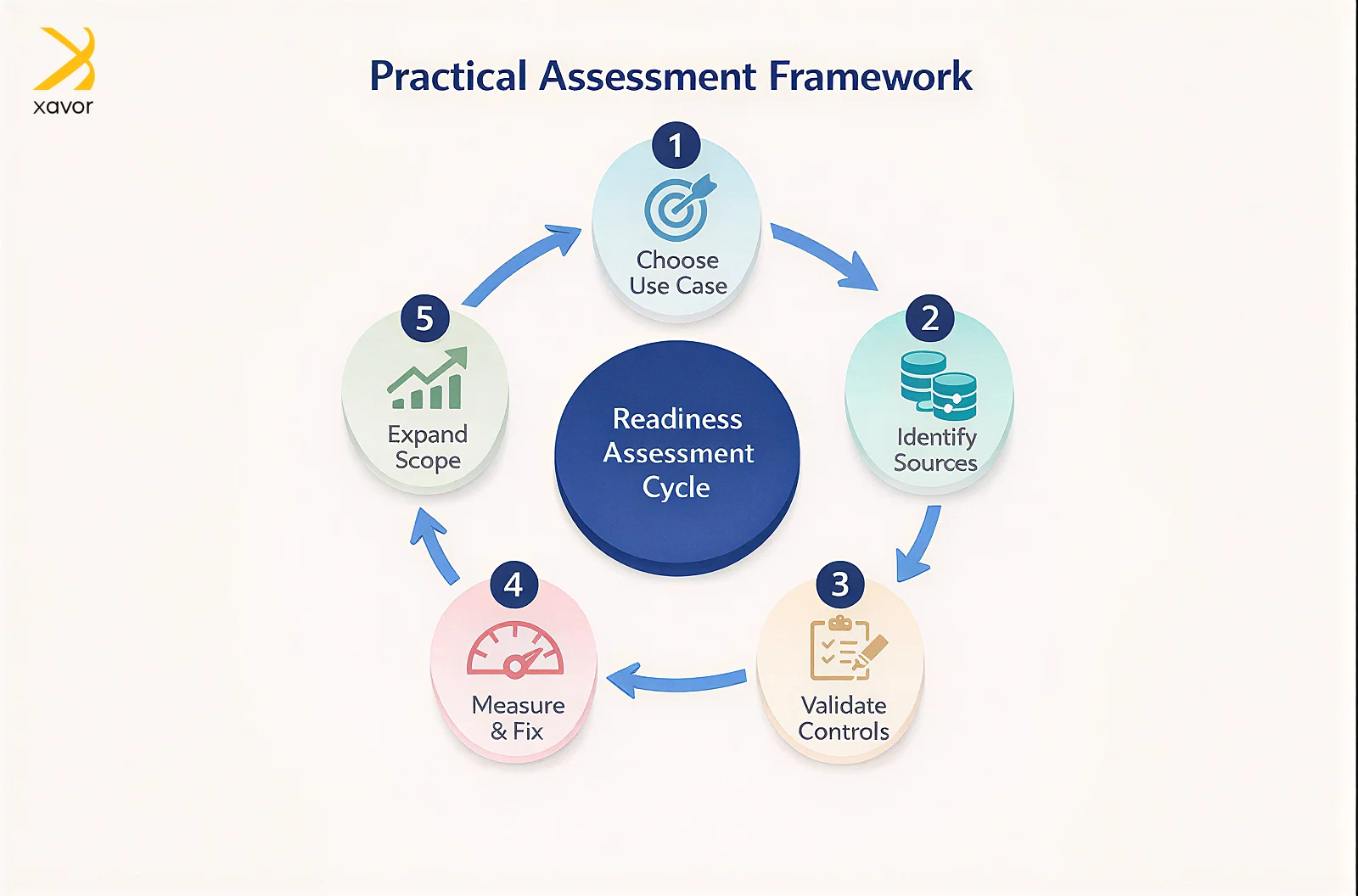
Organizations often stall by trying to prepare all enterprise data at once. That approach delays value and increases complexity. A practical readiness assessment starts with a narrow scope.
Choose one agent use case that relies heavily on enterprise data and carries moderate risk. Identify the exact enterprise data sources involved. Validate ownership, definitions, access rules, quality checks, and lineage for those sources. Introduce evaluation using AI training data services, measure outcomes, fix gaps, and then expand.
This method keeps enterprise data management work tied to real agent behavior, rather than theoretical completeness.
Why AI training data services become operational infrastructure
As agents become part of daily workflows, evaluation can no longer be informal. Organizations need continuous evidence that agents retrieve the correct enterprise data, apply rules consistently, and avoid restricted content. This is where training data services play a central role.
AI training data services support data readiness for AI by producing labeled datasets that reflect real enterprise workflows. These datasets are used to test retrieval of accuracy, output correctness, and policy compliance. They also support regression testing when enterprise data changes, which happens frequently in large organizations.
Without this capability, teams rely on anecdotal testing and production feedback. With it, enterprise data management gains a feedback loop that links agent behavior back to data quality, definitions, and governance controls.
Conclusion
The expected growth of agentic AI to $93.20B by 2032 shows how quickly enterprises will adopt systems that can work across data and take action. But success will not depend on how advanced the agent looks. It will depend on whether enterprise data is accurate, consistent, governed, and ready to be used safely across systems.
Enterprise data readiness is built on simple but critical foundations: clear data ownership, shared definitions, data that is fresh enough for decisions, enforced access rules, and the ability to trace outcomes back to data sources. When these basics are in place, agentic AI can be trusted and scaled. When they are missing, agents may still act, but results become difficult to rely on.
At Xavor, we help organizations assess and improve data readiness for agentic AI using real use cases and practical validation. To learn how to prepare your enterprise data for agentic systems, contact us at [email protected].

FAQs
In simple words, it means your company’s data is reliable enough for AI to use on its own. The data should be correct, up to date, and consistent across systems (for example, “customer” means the same thing everywhere). It should also be secure, so the AI only accesses data it is allowed to use.
Normal AI mostly answers questions or shows information. Agentic AI is different because it can plan steps, pull data from multiple systems, and take actions. Because of this, it depends much more on enterprise data being accurate, well-defined, and governed. If the data is wrong, the AI’s actions can be wrong too.
Don’t try to clean everything. Start small: pick one useful AI task (like drafting a customer reply, preparing a compliance summary, or checking an order issue). List the exact data sources it will use. Then check a few basics: who owns the data, what the terms mean, how accurate it is, who can access it, and whether you can track where it came from. Fix the gaps for that one use case first, then expand step by step.