
In the words of statistician George E.P. Box, “All models are wrong, but some are useful.” Statistical models are simplifications of reality. So, they will always fall short of the complexities of the real world, no matter how useful they are.
But AI enthusiasts seem to ignore this reality. An AI model is an approximation of patterns in the training data. It’s a fantasy to think of AI models as a neat, representative, labelled dataset that mirrors the real world exactly. However, you can make this fantasy closer to reality with data fusion. It is a data management strategy that ensures an AI model is fed the right slice of reality.
So, in this blog, we want to drop our two cents on this topic. Hopefully, this information will help you build trustworthy AI solutions and systems.
The truth about AI training data
Denial is not just a river in Egypt. AI training data is a motley of fragmented sources and a lot of muddled inputs. Everyone wants large and diverse datasets to train their AI systems. But few are willing to clean up all the mess and integrate to produce a quality AI product.
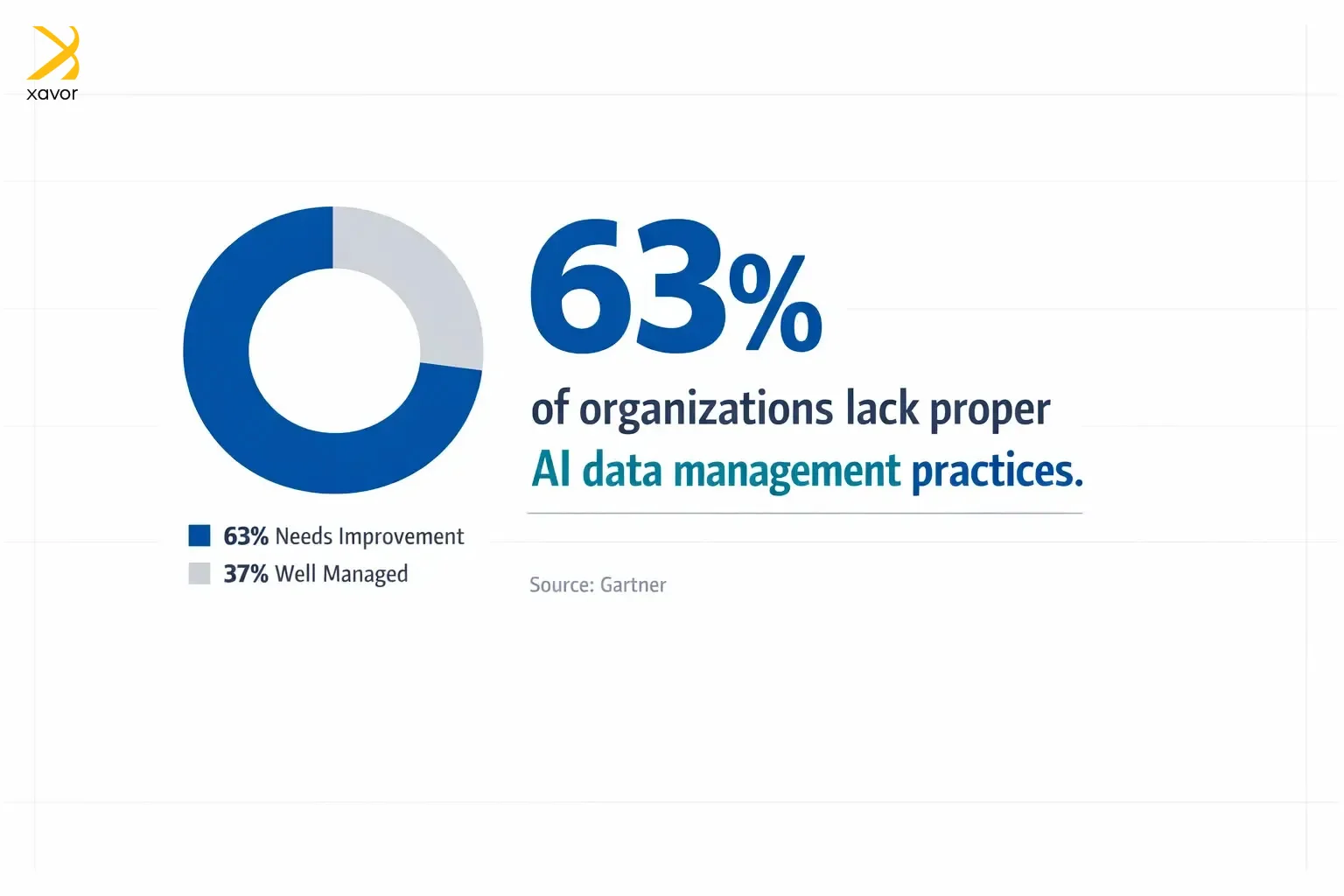
According to Gartner, 63% of organizations either don’t have, or aren’t sure they have, the right data management practices for AI. So, there is clearly something wrong with how companies approach training AI models.
In our opinion, that is out of negligence. Data management for AI is a higher bar than traditional BI and analytics, and a lot of organizations are trying to sprint to AI outcomes without rebuilding the plumbing.
What is data fusion?
Data fusion is the process of combining different kinds of data. It takes multiple datasets that describe the same real-world problem from different angles and combines them into one, more reliable view.
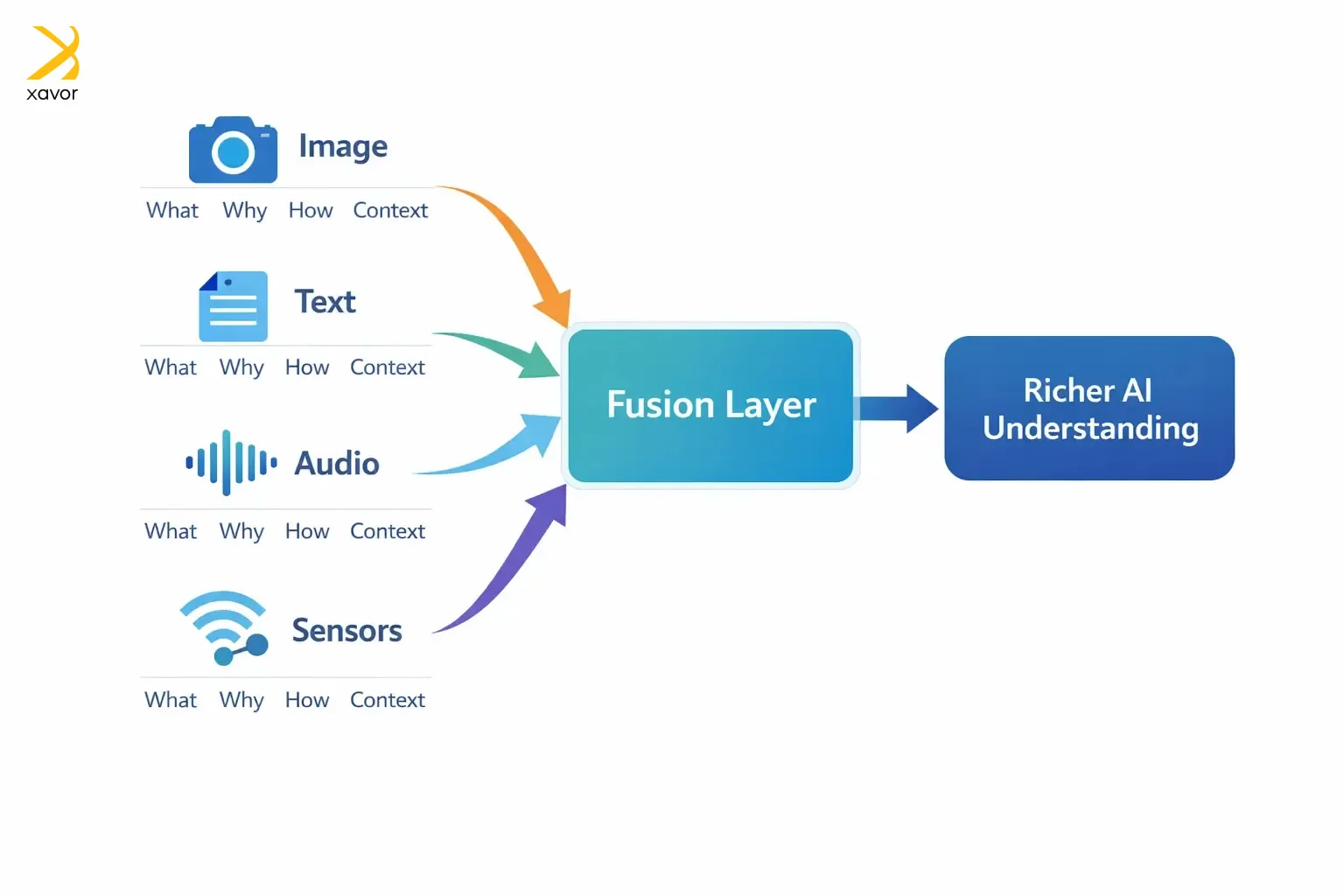
Each dataset is a partial perspective on the same phenomenon. An image may tell you what, but not the why. The relevant text may explain the why, but can’t answer the how. And for the how, you may need audio and sensory inputs. Fusion data intelligence brings them all together, so an AI system understands something more completely than it could from just one type of input.
Xavor’s way of multi-modal data fusion for AI applications
Our AI teams have developed real-world products for AI in healthcare, logistics, fintech, as well as in retail. That is why we know data pipeline development for different industries and use cases is vastly different.
Data fusion has some techniques and approaches that work best for certain situations. Therefore, this is how we go about multi-modal data fusion for AI applications, depending on the use case at hand.
1. Need instant context? Fuse early
Early fusion, as the name implies, combines data at the input stage. It is also sometimes called feature-level fusion. Instead of letting the AI process each modality separately and then merging the results later, you merge the raw inputs or simple early features first.
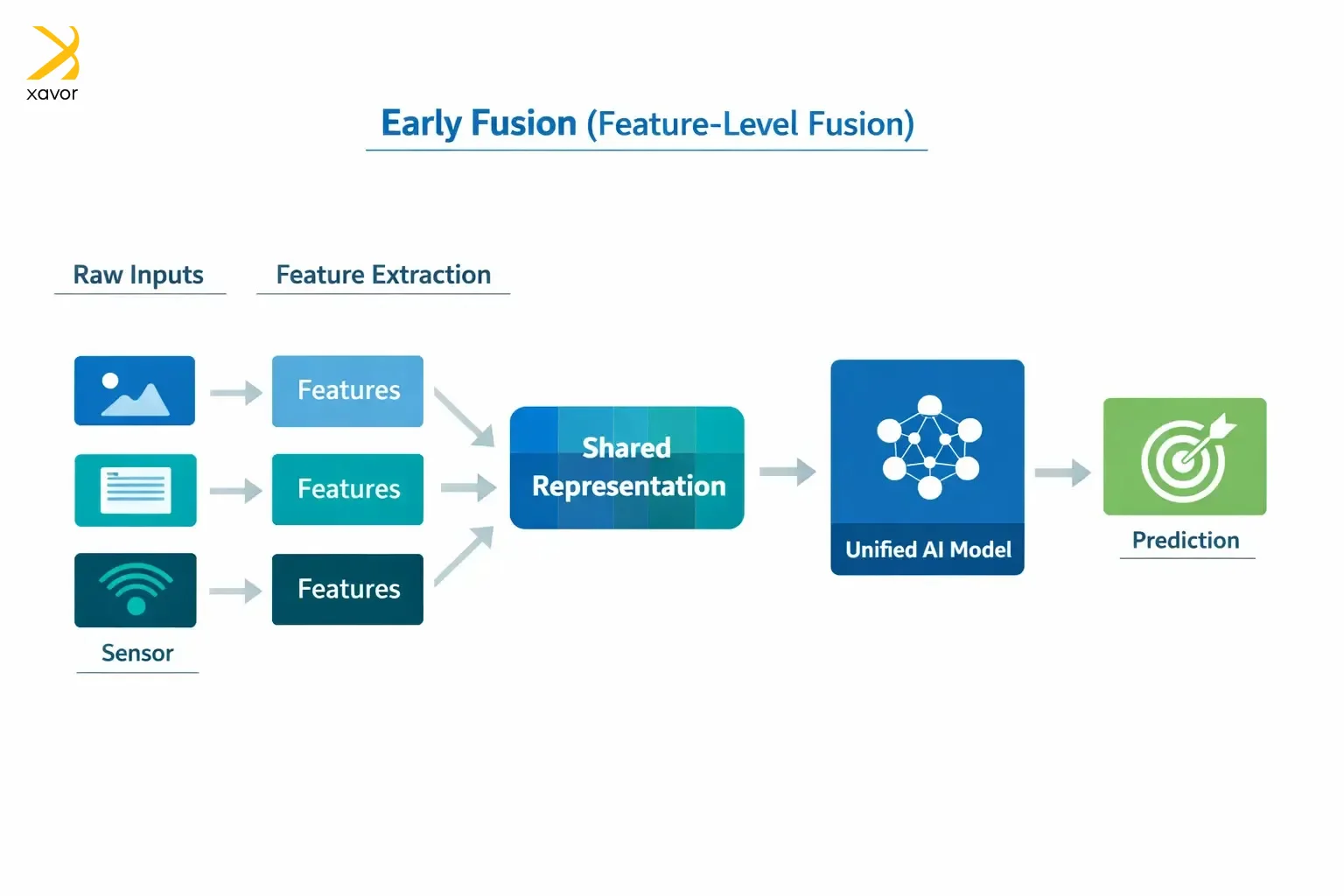
That creates one shared input representation that the model learns from in a single pass. For example, if you have an image and a short caption, early fusion is like joining the image features and the text features immediately, so the model learns patterns that connect them from the beginning.
Our data integration services prefer the early data fusion approach when the sources are time synchronized and refer to the same entity. And that is the case with our personal aide robot, Rui, which is an embodied AI designed for healthcare monitoring for elderly patients.
Rui collects concurrent signals like motion and patient activity. That is why early fusion is necessary to improve the detection of meaningful conditions because the interpretation depends on how signals co-vary in real time.
2. Late fusion for better reliability
Late fusion means you handle each type of data on its own, then combine the results at the end. So instead of mixing data early, you:
- Run a separate model for each modality
- Merge their outputs at the decision stage
That is why it is also called decision-level fusion. At Xavor, we use late data fusion when dealing with AI chatbots and industries like web security. For example, we design conversational AI products using late fusion on separate speech models that look at different audio representations and then combine their predictions. One model may catch details that the other misses, so the final result is more reliable.
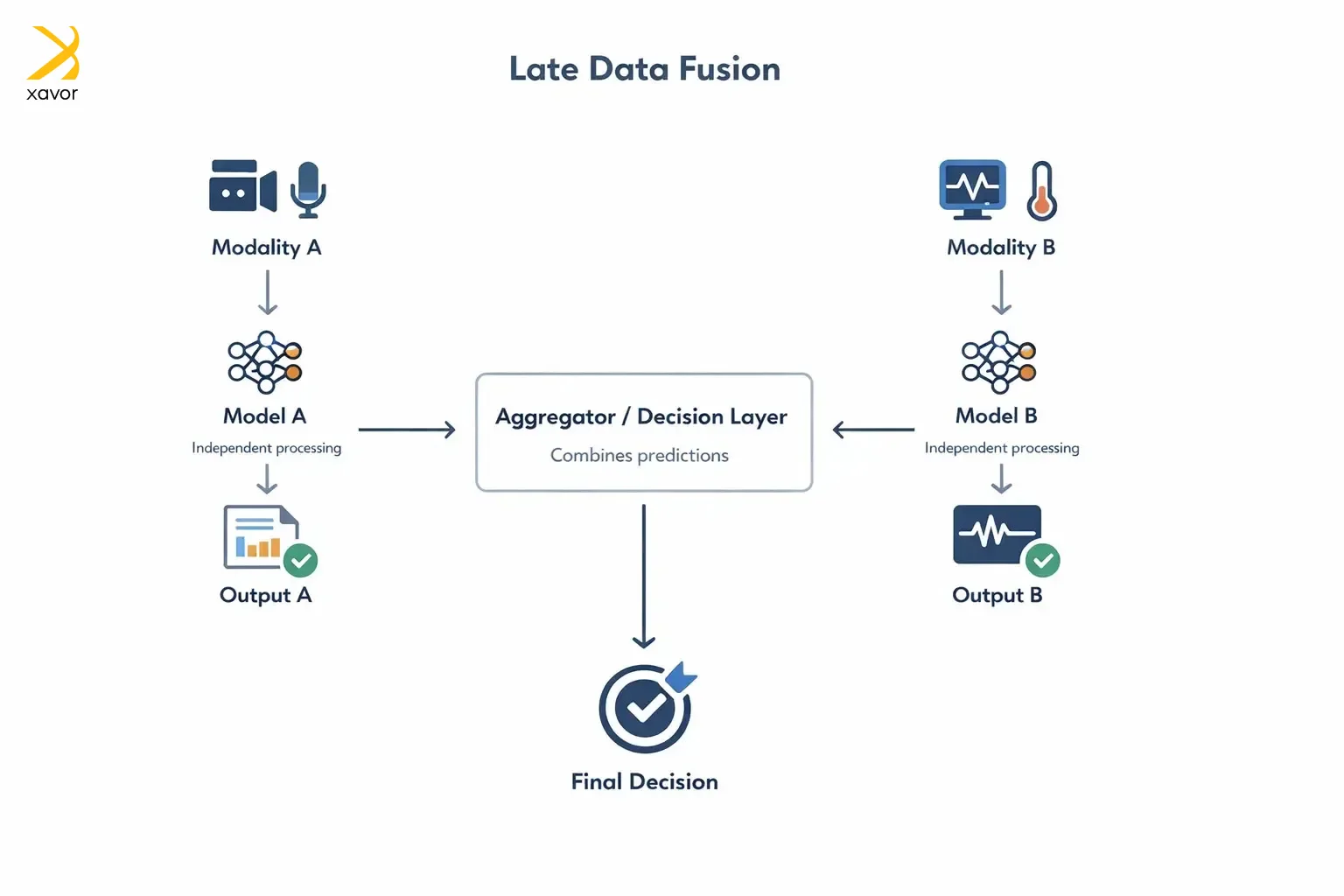
However, late fusion data pipeline development can’t fully learn how modalities influence each other. That can be an issue in cases where the meaning comes from the combination. Lastly, multi-modal data fusion for AI applications at the decision level becomes complex, which is why improving AI visibility is essential. The final result depends heavily on how you aggregate predictions. If the fusion method is poorly chosen, the combined decision can actually be worse than the best individual model, even if each model performs well on its own.
3. Hybrid fusion is the best of both worlds
Hybrid fusion mixes early and late fusion, so you get the benefits of both. It combines some information early, and others a bit late. The former allows modalities to interact during learning, while the latter enables the AI system to stay flexible.
Autonomous driving is the best use case for hybrid data fusion. Self-driving cars use LiDAR for real-time sensor interaction, but also modular safety layers and redundancy. Therefore, early fusion is needed between camera, radar, or LiDAR for perception. And late fusion comes in handy with rule-based safety checks or separate risk models.
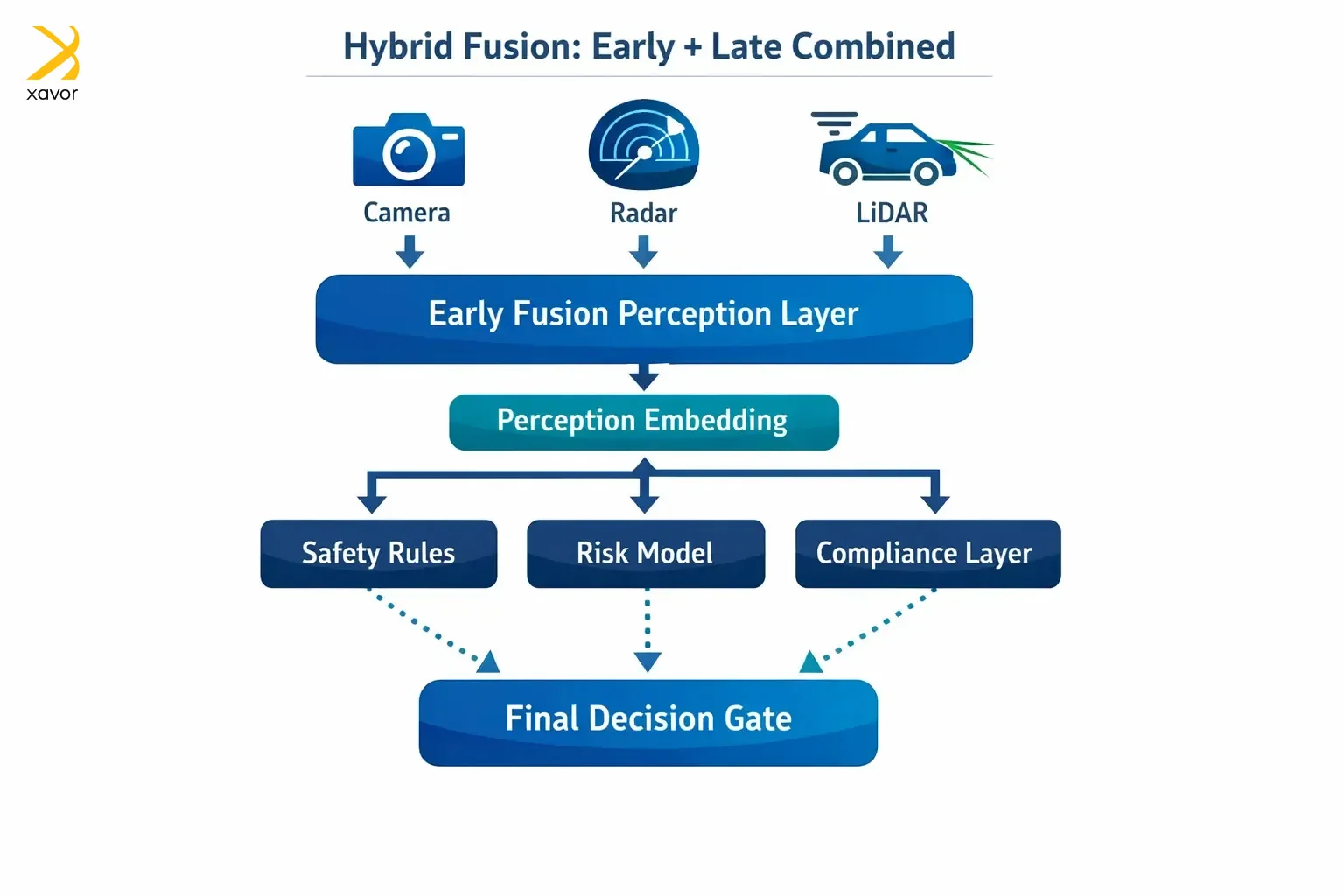
Here’s a vignette: We once built a fintech risk engine for a client using hybrid data fusion because our signals lived on different timelines and under different constraints. In real time, we fused behavior, session patterns, device fingerprints, and transaction attributes early so the model could learn the interactions that reveal fraud.
Then we fused regulated and slower-moving signals late, so those components stayed modular, auditable, and easy to govern. This gave us fast, accurate fraud decisions without sacrificing compliance or maintainability.
Industries that can use data fusion
Our clientele seeking data fusion solutions is quite diverse. You need a data management strategy, no matter what industry you work in, in 2026. That said, most of our clients from the following industries benefit the most from data fusion to create better AI systems.
1. Healthtech and life sciences
Creating a successful healthtech product is an uphill task. Particularly, a healthtech product with AI, because you have the dual challenges of accuracy and regulatory compliance. And data fusion is huge here because healthcare outcomes depend on multiple complementary signals.
A single decision that influences a patient’s life requires concurrent information from MRI, lab results, patient vitals, clinical notes, and wearable data. Fusing them improves diagnosis, triage, forecasting, and personalization.
2. Industrial operations
Even a medium-scale factory generates lots of sensor streams, records, reports, and operator notes. Data fusion helps industry managers with predictive maintenance and anomaly detection. That is an advantage because the why of a failure is usually spread across machines, history, and human observations.
3. Agriculture
In agriculture, data fusion is often used with remote sensing, so farmers can check the health of fields and pastures without physically walking through them. This way, farmers can assess plant conditions by looking at visual signals like leaf color, hue changes, and overall appearance, which can indicate stress, disease, or nutrient issues.
Data fusion taxonomy simplified
Okay, so data fusion taxonomy is a somewhat complex but very important concept of the whole process. We will try to simplify it for the “laity” in this section.
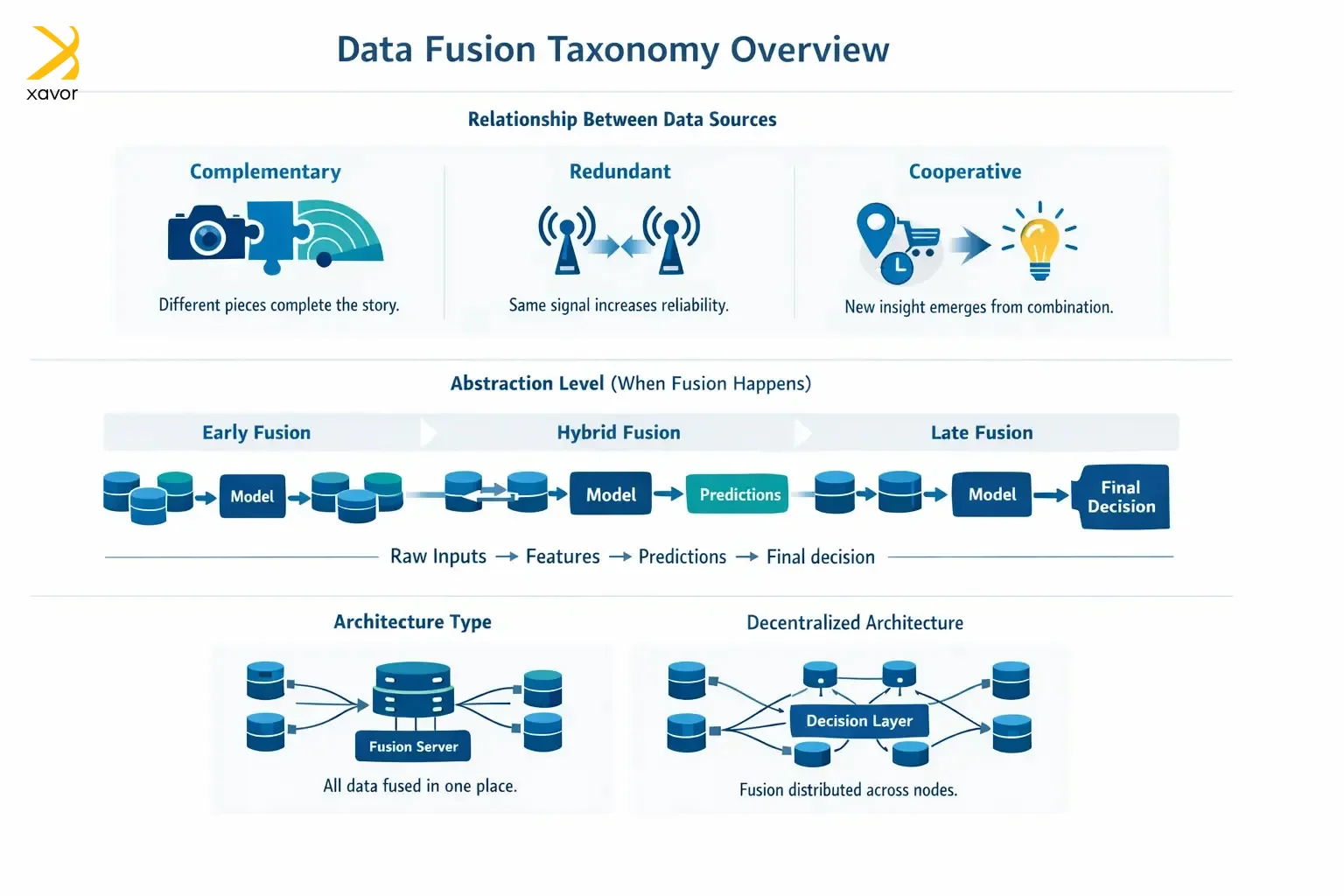
Because data fusion is used in so many industries, people made simple labels (taxonomies) to talk about it. Most taxonomies describe a data fusion solution by looking at what the data sources contribute, when the fusion happens, and how the system is structured.
1. Relationship between the data sources
How do the sources relate to each other? The answer to this question can be in any of the three ways.
| Relationship | What it means | Example |
| Complementary | Each source provides different pieces of the story. Together they fill gaps | A camera shows shape and color, while a radar shows distance and speed |
| Redundant | Multiple sources measure the same thing, mainly to increase reliability and reduce | Two sensors measuring temperature to confirm accuracy |
| Cooperative | Combining sources creates insight you couldn’t get from either alone, like something “new” emerges | Gathering location, purchase history, and time creates a stronger intent signal than any one source |
2. Input abstraction level
This label is concerned with where fusion happens in data pipeline development. Are you fusing raw-ish data or fusing final decisions? And we have already discussed early, late, and hybrid data fusion above.
3. Input and output abstraction levels
What form does the system accept, and what does it produce, is pertinent in data fusion techniques. For example, the fusion process may take extracted features and output a final classification.
On the other hand, another data management strategy can take raw or near-raw inputs and output a richer feature representation for later modeling. And there is a third possibility where the fusion takes predictions from multiple models and produces one final decision.
4. Architecture type
There are two ways you can decide where the fusion happens, which is called the architecture for the data fusion process.
- Centralized architecture: All data is collected in one place or a central system and fused there. Centralized architecture is easier to manage, but it can be slow or even impossible when data is distributed or private.
- Decentralized architecture: Fusion is done across multiple nodes, and only partial results are shared. Doing things this way is better for large networks or if you have privacy constraints. But the coordination in decentralized architecture is harder.
Conclusion
AI is now beyond text and numbers. There are varied input streams coming from different channels that run modern AI systems. And traditional AI models can’t really get the value out of this data.
Multi-modal data fusion for AI applications is the logical next step for businesses. It gives in-depth context about business data, which is the buttress of a strong data foundation. And Xavor helps you with reliable multimodal data collection and fusion.
We are a global provider of data integration services and fusion data intelligence development for AI platforms. Our customized services collect the best data for the job, whether it’s in healthcare, manufacturing, or any other industry. And then we design the data fusion workflows with complete annotation.
Contact us at [email protected] to book a free discovery call with our data experts.

FAQs
Data fusion means combining data from multiple sources, like sensors, logs, text, or images into one clearer, more reliable view. Blending these perspectives lets AI systems to make better predictions and decisions than they could using any single dataset alone.
Hank Asher was an American businessman who is known as the father of data fusion by industry insiders. He pioneered large-scale data integration systems that fused criminal records, public records, and investigative data to uncover hidden relationships.
Use data fusion when one dataset can’t give you the full picture because it’s incomplete, noisy, biased, or missing context. It’s especially useful when multiple sources describe the same thing from different angles and combining them can improve accuracy and decision-making.